NoSQL Overview
Not Only SQL refers to a family of databases that vary widely in style and technology. All share a common trait in that they are non relational in nature. Meaning they are not a standard row and column relational database management system or RDBMS. Therefore, a better name to describe these databases would be non relational.
- NoSQL databases don’t require fixed schemas, making them suitable for evolving use cases.
- NoSQL databases horizontally scale easily, allowing you to add more capacity for data and traffic as the demand grows.
- NoSQL databases are distributed systems that also provide native fault tolerance and availability.
In the late 2000s, several new databases emerged on the scene, many of them from open source communities. Databases like
- Apache Cassandra
- Mongo
- React
- couchDB
- HBase, Redis and neo4j became more prevalently used in applications. Particularly in ones that required larger scale than a relational database could manage.
In the last ten years or so, several NoSQL databases have leveraged a fully managed service model, otherwise called database as a service or DBaaS. Examples include IBM Cloudant and Amazon DynamodB.
Capabilities
- NoSQL capabilities support a flexible data model, which means you can store unstructured or semi structured data more easily.
- Some NoSQL databases provide native, built in horizontal and vertical scaling capabilities.
- Developers can work faster and more productively with data structures that match the application’s needs for reads and writes.
- NoSQL databases work in distributed environments and provide high availability and fault tolerance.
Examples:
- Social media platforms use document databases to manage user profiles.
- Column databases store user activity feed information
- Key value databases help organizations manage user sessions and speed user access to frequently access data.
- Graph databases do the essential work of keeping people connected by storing information about friends and relationships.
Open Source
There is some overlap among these types, so the definition isn’t always clear. One commonality is that the majority of them have their roots in the open-source community and have been used and leveraged in an open-source manner.
This has been fundamental for spring-boarding their growth in the industry. You’ll often see companies who also provide a commercial version of the database, and services and support of the technology, at the same time providing sponsorship of the open-source counterpart. Examples of this include:
- IBM Cloudant for CouchDB
- Datastax for Apache Cassandra
- Mongo has their own open source version of the Mongo database too
Commonalities
Technically speaking they all differ quite a bit, but a few commonalities do emerge.
- Most NoSQL databases are built to scale horizontally and share their data more easily than their relational counterparts. To do this often requires the use of a global unique key across a whole database, to simplify partitioning (or ‘sharding’).
- They’re also more specialized to certain use cases than RDBMS, which previously have been the Swiss army knives of datastores.
- Developers are drawn to NoSQL databases for their ease of data modeling and use.
- Many NoSQL databases allow more agile development through their flexible schemas as compared to the fixed schemas of relational databases.
Why Use NoSQL
Not all NoSQL databases will exhibit all of these benefits:
- First, the most common reason to employ a NoSQL database is for scalability, particularly the ability to horizontally scale across clusters of servers, racks, and possibly even data centers. The elasticity of scaling both up and down to meet the varying demands of applications is key.
- The second point of performance goes hand-in-hand with scalability. The need to deliver fast response times even with large data sets and high concurrency is a must for modern applications, and the ability of NoSQL databases to leverage the resources of large clusters of servers makes them ideal for fast performance in these circumstances.
- High availability is an obvious requirement for a database, and having a database run on a cluster of servers with multiple copies of the data makes for a more resilient solution than a single server solution. Historically, large databases have run on expensive machines or mainframes. Modern enterprises are employing cloud architectures to support their applications, and the distributed data nature of NoSQL databases means that they can be deployed and operated on clusters of servers in cloud architectures, thereby massively reducing cost.
- Cost is important for any technology venture, and it is common to hear of NoSQL adopters cutting significant costs versus their existing databases… and still be able to get the same or better performance and functionality.
- Flexible schema and intuitive data structures are key features that developers love when wanting to build applications efficiently. Most NoSQL databases allow for having flexible schemas, which means that one can build new features into applications quickly and without any database locking or downtime.
- NoSQL databases also have varied data structures, which often are more eloquent for solving development needs than the rows and columns of relational datastores. Examples include key-value stores for quick lookup, document stores for storing de-normalized intuitive information, and graph databases for associative data sets.
- There are also various specialized capabilities that certain NoSQL providers offer that attract end users.
Types
There is a general consensus that they fit into four types: Key-Value, Document, Column-based and Graph style NoSQL databases.
Document NoSQL
Document-store databases, also known as document-oriented databases, store data in a document format, typically JSON or BSON (binary JSON), where each document contains key-value pairs or key-document pairs. These databases are schema-less, allowing flexibility in data structures within a collection.
Characteristics
- Values are visible and can be queried
- Each piece of data is considered a document: typically
- JSON or
- XML
- Each document offers a flexible schema: No two documents are alike nor do they need to contain the same information
- Provides schema flexibility: Documents within collections can have varying structures, allowing for easy updates and accommodation of evolving data requirements.
- Performs efficient create, read, update, and delete (CRUD) operations: well-suited for read and write-intensive applications due to their ability to retrieve whole documents.
- Provides scalability: horizontal scalability by sharding data across clusters.
- Content can be indexed and queried using
- Key and Value range lookups and search
- Analytical queries with MapReduce
- Horizontally scalable
- Allow sharding across multiple nodes
- Typically only guarantee atomic operations on single documents
Use cases
- Content management systems (CMS): CMS platforms like WordPress use document store databases for fast storage and access to content types such as articles, images, and user data. (MongoDB)
- E-commerce: E-commerce platforms need effective management of product catalogs with diverse attributes and hierarchies, accommodating the dynamic nature of e-commerce product listings. (Couchbase or Amazon DocumentDB, using MongoDB compatibility)
- Event logging for apps and processes: each event instance is represented by a new document
- Online blogs: each user, post, comment, like, or action is represented by a document
- Operational datasets and metadata for web and mobile apps
Unsuitable
- When you require ACID transactions
- Cannot handle transactions that operate over multiple documents
- RDBMS would be better suited
- When your data is in an aggregate-oriented design:
- If data naturally falls into a normalized tabular model
Vendors
- MongoDB
- Couchbase
- Amazon DocumentDB
Key-value NoSQL
Key-value stores are the simplest NoSQL databases, storing data as a collection of key-value pairs, where the key is unique and directly points to its associated value.

Characteristics
- Delivers high performance: efficient for read and write operations, optimized for speedy retrieval based on keys
- Provides scalability: easily scalable due to their simple structure and ability to distribute data across nodes
- Uses caching for fast access
- Provides session management
- Works with distributed systems
- Least complex
- Represented as a hashmap
- Ideal for CRUD operations
- Scales well
- Shards easily
Use cases
- Enhanced web performance by caching frequently accessed data (Using Redis or Memcached). Storing and retrieving session information for web-applications
- E-commerce platforms, shopping carts, software applications, including gaming: Amazon DynamoDB provides a highly scalable key-value store, facilitating distributed systems’ seamless operation by handling high traffic and scaling dynamically.
- For quick basic CRUD operations on non-interconnected data
- Storing in-app user profiles and preferences
Unsuitable
- Interconnected data with many-to-many relationships: social networks, recommendation engines
- When high-level of consistency is required for multi-operation transactions with multiple keys
- When apps run queries based on value vs key instead of key vs value
Vendors
- Redis
- Memcached
- Amazon DynamoDB
- Oracle NoSQL db
- Aerospike
- Riak KV, MemcacheDB
Column-family NoSQL
Column-family stores NoSQL databases, also referred to as columnar databases, organize data in columns rather than rows. These databases store columns of data together, making them efficient for handling large data sets with dynamic schemas.
Characteristics
- Uses column-oriented storage: Data is grouped by columns rather than rows, allowing for efficient retrieval of specific columns.
- Delivers scalability: Distributed architecture for high availability and scalability.
These databases are also commonly referred to as Bigtable clones, columnar databases, or wide-column databases. As you can tell from the name, these databases focus on columns and groups of columns when storing and accessing data.
- The column named families consists of several rows.
- Each row has a unique key or identifier that belongs to one or more columns.
- These columns are grouped together in families because they are often accessed together.
- Rows in a column family are not required to share any of the same columns.
- Rows can share all columns, a subset of columns, or none of the columns, and columns can be added to some rows and not to others.
Use cases
- IoT applications manage massive amounts of sensor data efficiently due to their ability to handle time-stamped data at scale, referred to as time-series data analysis. (Apache Cassandra)
- Applications that store and analyze user preferences and behaviors usually deliver personalization. (HBase, part of the Hadoop ecosystem)
- Large-scale data analysis when you’re dealing with large amounts of sparse data. When compared to row-oriented databases, column-based databases can better compress data and save storage space. In addition, these databases continue the trend of horizontal scalability.
- As with key value and document databases, column-based databases can handle being deployed across clusters of nodes.
- Like document databases, a column-based NoSQL database can be used for event logging and blogs, but the data would be stored in a different fashion.
- For enterprise event logging, every application can write to its own set of columns and have each row key formatted in such a way to promote easy lookup based on application and timestamp.
- Counters are a unique use case for column-based databases. You may come across applications that need an easy way to count or increment as events occur. Some column-based databases, like Cassandra have special column types that allow for simple counters.
- In addition, columns can have a time-to-live parameter, making them useful for data with an expiration date or time like trial periods or ad timing.
Unsuitable
- If you require traditional asset transactions provided by relational databases. Reads and writes are only atomic at the row level.
- And early into development, query patterns may change and require numerous changes to the column-based designs. This can be costly and slow down the development timeline.
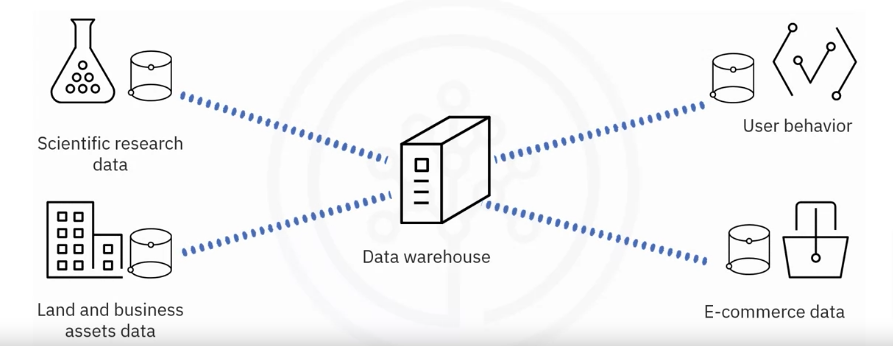
In a typical data warehousing scenario, you need to collect and store data from different sources, including research such as scientific research, land and business assets, user behavior, and ecommerce data.
- Row-oriented databases in data warehouses store a record or row data in contiguous blocks, while
- column database stores the record using contiguous columns.
This data storage method facilitates faster access to the data, enhancing an organization’s business intelligence and reporting capabilities.
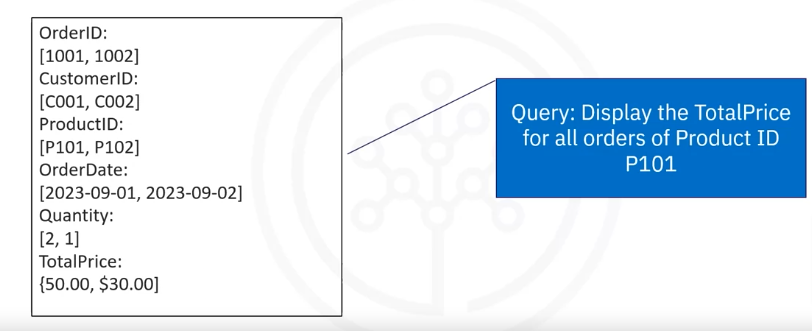
Let’s examine how the company would store ecommerce data in a column-oriented database. In this simplified example, you can see each column or key name and its data, and when doing a query such as display the total price for all orders of product ID P101, the query only needs to read the product ID and the total price column data.
- Examine how data analysts can use columnar databases for their work.
- Financial analysis, online analytical processing, called OLAP, happens when analyzing data that doesn’t change often.
- When performing OLAP, you are working with a large number of records, but only analyzing a subset of the data stored within the columns.
For example, analyzing data to build a histogram of insurance premiums paid during the last financial year.
IoT devices are everywhere, you’ll find these devices in cars, trucks, cameras, smartphones, and even light bulbs and luggage, capturing data on demand continuously or periodically. Storing this data in a traditional database requires a lot of data storage space, and data access can suffer latency. Because IoT data is often used for real time and near real-time analysis, including visualizations, data analysts do not want to incur long wait times when querying data.
Columnar databases help resolve these problems, helping to provide efficient storage and timely access to IoT data.
Vendors
- Apache Cassandra
- HBase
Wide-column NoSQL
Wide-column store NoSQL databases organize data in tables, rows, and columns, like relational databases, but with a flexible schema.
Characteristics
- Use columnar storage: Data is stored in columns, allowing for efficient retrieval of specific columns rather than entire rows.
- Provide horizontal scalability and fault tolerance.
Use cases
- Analyzing big data: Efficiently handling large-scale data processing for real-time big data analytics. (Apache HBase used in conjunction with Hadoop)
- Managing enterprise content: Large organizations databases need to manage vast amounts of structured data like employee records or inventory due. (Cassandra)
Vendors
- Apache HBase
- Apache Cassandra
Graph NoSQL
Graph NoSQL databases are designed to manage highly interconnected data, representing relationships as first-class citizens alongside nodes and properties.
Characteristics
- Store information in entities (or nodes) and relationships (or edges)
- Very impressive when your data set resembles a graph-like data structure
- These dbs do NOT shard well, traversing a graph with nodes split across multiple servers can become difficult and hurt performance
- Graph DBs are ACID transaction compliant (unlike other NoSQL dbs), this prevents any dangling relationships between nodes that don’t exist
- Analyzes the data using a graph data model: relationships are as important as the data itself, enabling efficient traversal and querying of complex relationships.
- Fast performance for relationship queries: optimized for queries involving relationships, making them ideal for social networks, recommendation systems, and network analysis.
Use cases
- Social networks require efficient data management of relationships between users, posts, comments, and likes. (Neo4j)
- Recommendation systems: Organizations need a database structure that can create sophisticated recommendation engines, analyzing complex relationships between users, products, and behaviors for precise recommendations. (Amazon Neptune)
- Highly connected and related data
- Routing, spatial, and map apps
- Recommendation engines
Unsuitable
- When an application needs to scale horizontally
- When trying to update all or a subset of nodes with a given parameter
Vendors
- Neo4j
- Amazon Neptune
- ArangoDB Memcached