Hadoop Overview
Before we get into Hadoop let’s look at how we got there: Big Data
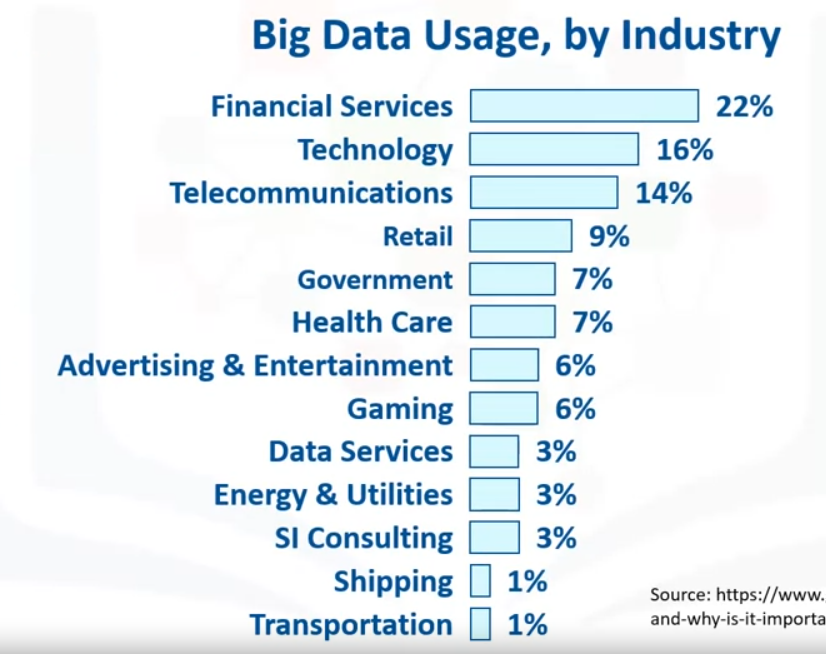
Some industries contributing to Big Data:
- Retail
- Price analytics, segmentation, price points, margin analysis, sentiment analysis, marketing strategies
- Insurance
- Fraud analytics, anomalies detection, risk assessment, predictive modeling to identify high-risk customers
- Telecommunications
- Network security, location-based promotions, network analytics, optimized pricing
- Manufacturing
- Predictive maintenance, production optimization
- Automotive Industry
- Predictive support regarding malfunctions, pre-emptive ordering of parts, repair, self-driven cars, real-time data analysis for autonomous driving
- Finance
- Customer segmentation, targeting marketing, customer demographics, transaction frequency, behavior patterns, social media posts and interactions with customer service systems, algorithmic trading, ML based decisions using instant analysis of large quantities of data
Hadoop is an open-source framework used to process enormous datasets. Hadoop is a set of open-source programs and procedures which can be used as the framework for Big Data operations. It is used for processing massive data in distributed file systems that are linked together. It allows for running applications on clusters. (A cluster is a collection of computers working together at the same to time to perform tasks. )
It should be noted that Hadoop is not a database but an ecosystem that can handle processes and jobs in parallel or concurrently.
Hadoop is optimized to handle massive quantities of data which could be:
- Structured
- Tabular
- Unstructured
Core Components
The term Hadoop is often used to refer to both the core components of Hadoop as well as the ecosystem of related projects. The core components of Hadoop include:
Hadoop Common
Hadoop Common, which is an essential part of the Apache Hadoop Framework that refers to the collection of common utilities and libraries that support other Hadoop modules.
HDFS
There is a storage component called Hadoop Distributed File System, or HDFS. It handles large data sets running on commodity hardware.
A commodity hardware is low-specifications industry-grade hardware and scales a single Hadoop cluster to hundreds or even thousands.
MapReduce
MapReduce is a processing unit of Hadoop and an important core component to the Hadoop framework. MapReduce processes data by splitting large amounts of data into smaller units and processes them simultaneously.
For a while, MapReduce was the only way to access the data stored in the HDFS. There are now other systems like Hive and Pig.
Yarn
YARN, which is short for “Yet Another Resource Negotiator.” YARN is a very important component because it prepares the RAM and CPU for Hadoop to run data in batch processing, stream processing, interactive processing, and graph processing, which are stored in HDFS.
Hadoop Ecosystem
The Hadoop ecosystem is made up of components that support one another for Big Data processing. We can examine the Hadoop ecosystem based on the various stages.
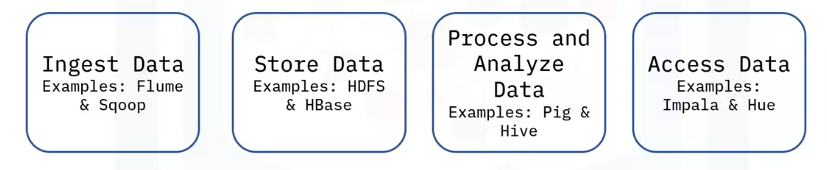
Ingest Data
When data is received from multiple sources, Flume and Sqoop are responsible for ingesting the data and transferring them to the storage component.
Ingesting is the first stage of Big Data processing.
- Whenever you deal with big data, you get data from different sources.
- You then use tools like Flume and Sqoop.
Flume
- Flume is a distributed service that collects, aggregates, and transfers Big Data to the storage system.
- Flume has a simple and flexible architecture based on streaming data flows and uses a simple extensible data model that allows for online analytic application.
Sqoop
- Sqoop is an open-source product designed to transfer bulk data between relational database systems and Hadoop.
- Sqoop looks in the relational database and summarizes the schema.
- It then generates MapReduce code to import and export data as needed.
- Sqoop allows you to quickly develop any other MapReduce applications that use the records that Sqoop stored into HDFS.
Storage Component
The Storage component, HDFS and HBase.
HBase
HBase is a column-oriented non-relational database system that runs on top of HDFS.
- It provides real time wrangling access to the Hadoop file system.
- HBase uses hash tables to store data in indexes and allow for random access of data, which makes lookups faster.
Cassandra
Cassandra is a scalable, NoSQL database designed to have no single point of failure.
Process & Analyze Data
From HDBS the data is Distributed to a MapReduce framework like Pig and Hive to process and analyze the data, and the processing is done by parallel computing.
Pig
In the Analyze Data stage, Pig is used for analyzing large amounts of data.
- Pig is a procedural data flow language and a procedural programming language that follows an order and set of commands.
Hive
Hive is used mainly for creating reports and operates on the server side of a cluster.
- Hive is a declarative programming language, which means it allows users to express which data they wish to receive.
Access Data
After all the processing is done, tools like Hue are used to access the refined data. The final stage is “Access data,” where users have access to the analyzed and refined data. At this stage tools like Impala are often used.
Impala
Impala is a scalable system that allows non-technical users to search and access the data in Hadoop.
- You do not need to be skilled in programming to use Impala.
Hue
Hue is another tool of choice at this stage.
- Hue is an acronym for Hadoop user experience.
- Hue allows you to upload, browse, and query data.
- You can run Pig jobs and workflow in Hue.
- Hue also provides a SQL editor for several query languages like Hive, and MySQL.
Drawbacks
Hadoop contained many smaller components. Although efficient at first glance, Hadoop failed at simple tasks.
Transaction Processing
Hadoop is not good for processing transactions due to its lack of random access.
Non-parallel Processing
Hadoop is not good when the work cannot be done in parallel
Dependencies in Data
Hadoop is not good when there are dependencies within the data. Dependencies arise when record one must be processed before record two.
Low Latency Access
Hadoop is also not good for low latency data access. “Low latency” allows small delays, unnoticeable to humans, between an input being processed and the corresponding output providing real time characteristics.
This can be especially important for
- Internet connections utilizing services such as trading,
- online gaming
- Voice over IP
Small Files
Hadoop is also not good for processing lots of small files, although, there is work being done in this area such as IBM’s Adaptive MapReduce.
Intensive Calculations with Little Data
Hadoop is not good for intensive calculations with little data.
Remedies
- To deal with the shortcomings of Hadoop, new tools like Hive were built on top of Hadoop. Hive provided SQL-like query and provided users with strong statistical functions.
- Pig was popular for its multi query approach to cut down the number of times that the data is scanned.
Cheat Sheet 1
| Term | Definition |
|---|---|
| Anomaly detection | A process in machine learning that identifies data points, events, and observations that deviate from a data set’s normal behavior. Detecting anomalies from time series data is a pain point that is critical to address for industrial applications. |
| Apache | This open-source HTTP server implements current HTTP standards to be highly secure, easily configurable, and highly extendible. The Apache Software License by the Apache Software Foundation builds and distributes it. |
| Apache Cassandra | It is a scalable, NoSQL database specifically designed not to have a single point of failure. |
| Apache Nutch | An extensible and scalable web crawler software product to aggregate data from the web. |
| Apache ZooKeeper | A centralized service for maintaining configuration information to maintain healthy links between nodes. It provides synchronization across distributed applications. It also tracks server failure and network partitions by triggering an error message and then repairing the failed nodes. |
| Big data | Data sets whose type or size supersedes the ability of traditional relational databases to manage, capture, and process the data with low latency. Big data characteristics include high volume, velocity, and variety. |
| Big data analytics | Uses advanced analytic techniques against large, diverse big data sets, including structured, semi-structured, and unstructured data, from varied sources and sizes, from terabytes to zettabytes. |
| Block | Minimum amount of data written or read, and also offers fault tolerance. The default block size can be 64 or 128 MB, depending on the user’s system configuration. Each file stored need not take up the storage of the preconfigured block size. |
| Clusters | These servers are managed and participate in workload management. They allow enterprise applications to supersede the throughput achieved with a single application server. |
| Command-line interface (CLI) | Used to enter commands that enable users to manage the system. |
| Commodity hardware | Consists of low-cost workstations or desktop computers that are IBM-compatible and run multiple operating systems such as Microsoft Windows, Linux, and DOS without additional adaptations or software. |
| Data ingestion | The first stage of big data processing. It is a process of importing and loading data into IBM® WatsonX.data. You can use the Ingestion jobs tab from the Data manager page to load data securely and easily into WatsonX.data console. |
| Data sets | Created by extracting data from packages or data modules. They gather a customized collection of items that you use frequently. As users update their data set, dashboards and stories are also updated. |
| Data warehouse | Stores historical data from many different sources so users can analyze and extract insights from it. |
| Distributed computing | A system or machine with multiple components on different machines. Each component has its own job, but the components communicate with each other to run as one system for the end user. |
| Driver | Receives query statements submitted through the command line and sends the query to the compiler after initiating a session. |
| Executor | Executes tasks after the optimizer has split the tasks. |
| Extended Hadoop Ecosystem | Consists of libraries or software packages commonly used with or installed on top of the Hadoop core. |
| Fault tolerance | A system is fault-tolerant if it can continue performing despite parts failing. Fault tolerance helps to make your remote-boot infrastructure more robust. In the case of OS deployment servers, the whole system is fault-tolerant if the servers back up each other. |
| File system | An all-comprehensive directory structure with a root ( / ) directory and other directories and files under a logical volume. The complete information about the file system centralized in the /etc/filesystems file. |
| Flume | A distributed service that collects, aggregates, and transfers big data to the storage system. Offers a simple yet flexible architecture that streams data flows and uses an extensible data model, allowing online analytic applications. |
| Hadoop | An open-source software framework offering reliable distributed processing of large data sets using simplified programming models. |
| Hadoop Common | Fundamental part of the Apache Hadoop framework. It refers to a collection of primary utilities and libraries that support other Hadoop modules. |
| Hadoop Distributed File System (HDFS) | A file system distributed on multiple file servers, allowing programmers to access or store files from any network or computer. It is the storage layer of Hadoop. It works by splitting the files into blocks, creating replicas of the blocks, and storing them on different machines. It can access streaming data seamlessly. It uses a command-line interface to interact with Hadoop. |
| Hadoop Ecosystem | It splits big data analytics processing tasks into smaller tasks. The small tasks are performed in conjunction using an algorithm (MapReduce) and then distributed across a Hadoop cluster (nodes that perform parallel computations on big data sets). |
| Hadoop Ecosystem stages | The four main stages are: Ingest, store, process, analyze, and access. |
| HBase | A column-oriented, non-relational database system that runs on top of the Hadoop Distributed File System (HDFS). It provides real-time wrangling access to the Hadoop file system. It uses hash tables to store data in indexes and allow for random data access, making lookups faster. |
| High-throughput | Throughput quantifies the data processed in a timeframe. The target system needs robust throughput for heavy workloads with substantial data changes from the source database to prevent latency spikes. Performance objectives are frequently outlined with throughput targets. High throughput is achieved when most messages are delivered successfully, whereas low successful delivery rates indicate poor throughput and network performance. |
| Hive | It is a data warehouse infrastructure used in data query and analysis with an SQL-like interface. It helps in generating and creating reports. It is a declarative programming language allowing users to express which data they wish to receive. |
| Hive client | Hive provides different communication drivers depending on the application type. For example, Java-based applications use JDBC drivers, and other applications use ODBC drivers. These drivers communicate with the servers. |
| Hive server | Used to execute queries and enable multiple clients to submit requests. It can support JDBC and ODBC clients. |
| Hive services | Client interactions and query operations are done through the Hive services. The command-line interface acts as an interface for the Hive service. The driver takes in query statements, monitors each session’s progress and life cycle, and stores metadata generated from the query statements. |
| Hive Web Interface | A web-based user interface that interacts with Hive through a web browser. It offers a graphical user interface (GUI) to browse tables, execute Hive queries, and manage Hive resources. |
| HMaster | The master server that monitors the region server instances. It assigns regions to region servers and distributes services to different region servers. It also manages any changes to the schema and metadata operations. |
| Hue | An acronym for Hadoop user experience. It allows you to upload, browse, and query data. Users can run Pig jobs and workflow in Hue. It also provides an SQL editor for several query languages, like Hive and MySQL. |
| Impala | A scalable system that allows nontechnical users to search for and access the data in Hadoop. |
| InputSplits | Created by the logical division of data. They serve as an input to a single Mapper job. |
| JDBC client | Component in the Hive client allows Java-based applications to connect to Hive. |
| Low latency data access | A type of data access allowing minimal delays, not noticeable to humans, between an input processed and corresponding output offering real-time characteristics. It is crucial for internet connections using trading, online gaming, and Voice over IP. |
| Map | Job in MapReduce converts a set of data into another set of data. The elements fragment into tuples (key/value pairs). |
| MapReduce | A program model and processing technique used in distributed computing based on Java. It splits the data into smaller units and processes big data. It is the first method used to query data stored in HDFS. It allows massive scalability across hundreds or thousands of servers in a Hadoop cluster. |
| Meta store | Stores the metadata, the data, and information about each table, such as the location and schema. In turn, the meta store, file system, and job client communicate with Hive storage and computing to perform the following: Metadata information from tables store in some databases and query results, and data loaded from the tables store in a Hadoop cluster on HDFS. |
| Node | A single independent system for storing and processing big data. HDFS follows the primary/secondary concept. |
| ODBC (Open Database Connectivity) Client | Component in the Hive client, which allows applications based on the ODBC protocol to connect to Hive. |
| Optimizer | Performs transformations on the execution and splits the tasks to help speed up and improve efficiency. |
| Parallel computing | Workload for each job is distributed across several processors on one or more computers, called compute nodes. |
| Parser | A program that interprets the physical bit stream of an incoming message and creates an internal logical representation of the message in a tree structure. The parser also regenerates a bit stream from the internal message tree representation for an outgoing message. |
| Partitioning | This implies dividing the table into parts depending on the values of a specific column, such as date or city. |
| Pig Hadoop component | Famous for its multi-query approach, it analyzes large amounts of data. It is a procedural data flow and programming language that follows an order and set of commands. |
| Primary node | Also known as the name node, it regulates client file access and maintains, manages, and assigns tasks to the secondary node. The architecture is such that per cluster, there is one name node and multiple data nodes, the secondary nodes. |
| Rack | The collection of about forty to fifty data nodes using the same network switch. |
| Rack awareness | When performing operations such as read and write, the name node maximizes performance by choosing the data nodes closest to themselves. Developers can select data nodes on the same rack or nearby racks. It reduces network traffic and improve cluster performance. The name node keeps the rack ID information to achieve rack awareness. |
| Read | In this operation, the client will request the primary node to acquire the location of the data nodes containing blocks. The client will read files closest to the data nodes. |
| Reduce | Job in MapReduce that uses output from a map as an input and combines data tuples into small sets of tuples. |
| Region | The basic building element and most negligible unit of the HBase cluster, consisting of column families. It contains multiple stores, one for each column family, and has two components: HFile and MemStore. |
| Region servers | These servers receive read and write requests from the client. They assign the request to a region where the column family resides. They serve and manage regions present in a distributed cluster. The region servers can communicate directly with the client to facilitate requests. |
| Relational database | Data is organized into rows and columns collectively, forming a table. The data is structured across tables, joined by a primary or a foreign key. |
| Relational Database Management System (RDBMS) | Traditional RDBMS maintains a database and uses the structured query language, SQL. It is suited for real-time data analysis, like data from sensors. It allows for as many read-and-write operations as a user may require. It can handle up to terabytes of data. It enforces that the schema must verify loading data before it can proceed. It may not always have built-in support for data partitioning. |
| Replication | The process of creating a copy of the data block. It is performed by rack awareness as well. It is done by ensuring data node replicas are in different racks. So, if a rack is down, users can obtain the data from another rack. |
| Replication factor | Defined as the number of times you make a copy of the data block. Users can set the number of copies they want, depending on their configuration. |
| Schema | It is a collection of named objects. It provides a way to group those objects logically. A schema is also a name qualifier; it provides a way to use the same natural name for several objects and prevent ambiguous references. |
| Secondary node | This node is also known as a data node. There can be hundreds of data nodes in the HDFS that manage the storage system. They perform read and write requests at the instructions of the name node. They also create, replicate, and delete file blocks based on instructions from the name node. |
| Semi-structured data | Semi-structured data (JSON, CSV, XML) is the “bridge” between structured and unstructured data. It does not have a predefined data model and is more complex than structured data, yet easier to store than unstructured data. |
| Shuffle | Phase in which interim map output from mappers transfers to reducers. Every reducer fetches interim results for all values associated with the same key from multiple nodes. This is a network-intensive operation within the Hadoop cluster nodes. |
| Sqoop | An open-source product designed to transfer bulk data between relational database systems and Hadoop. It looks at the relational database and summarizes the schema. It generates MapReduce code to import and export data. It helps develop other MapReduce applications that use the records stored in HDFS. |
| Streaming | Implies HDFS provides a constant bitrate when transferring data rather than having the data transferred in waves. |
| Structured data | Structured data, typically categorized as quantitative data, is highly organized and easily decipherable by machine learning algorithms. Developed by IBM in 1974, structured query language (SQL) is the programming language used to manage structured data. |
| Unstructured data | Information lacking a predefined data model or not fitting into relational tables. |
| Write | In this operation, the Name node ensures that the file does not exist. If the file exists, the client gets an IO Exception message. If the file does not exist, the client is given access to start writing files. |
| Yet Another Resource Negotiator (YARN) | Prepares Hadoop for batch, stream, interactive, and graph processing. |
Cheat Sheet 2
| Package/Method | Description | Code Example |
|---|---|---|
| bin/hadoop | All Hadoop commands are invoked by the bin/hadoop script. Running the Hadoop script without any arguments prints the description for all commands. | Running Hadoop script without arguments: |
| cat | Reads each file parameter in sequence and writes it to standard output. If you do not specify a file name, the cat command reads from standard input. You can also specify a file name of - (dash) for standard input. | Create two sample files. Use the cat command to read and display the contents of both files Sample output (Contents of file1.txt and file2.txt): |
| cd | Used to move efficiently from the existing working directory to different directories on your system. | Basic syntax of cd command: Example 1: Change directory location to “folder1” Example 2: Get back to the previous working directory Example 3: Move up one level from the present working directory tree |
| create table | Used to create a new table in a database | Create a new database (if not already created). Use the newly created database. Create a new table named “employees” in Hive. Show the list of tables in the database. Sample Output (List of Tables): |
| curl | A command-line tool (pronounced “curl”) that allows data to be exchanged between a device and a server through a terminal. The user specifies the server URL, the location where they want to send the request, and the data they want to send to the server URL using this command-line interface (CLI). | Example 1: Sending a GET request and displaying the response Send a GET request to a server and display the response. In this example, we use the curl command to send a GET request to https://www.example.com and display the HTML response from the server. Example 2: Sending data to a server using POST Request: Send a POST request with data to a server and display the response. In this example, we use the curl command to send a POST request to https://www.example.com/api with data |
| docker exec | Runs a new command in a running container. It only runs when the container’s primary process is running, and it is not restarted if the container is restarted. | Running a command in a running Docker container: Run a new command inside a running Docker container. Sample Output (List of files in the ‘/app’ Directory inside the container): In this example:
|
| docker-compose | Compose is a tool for defining and running multi-container Docker applications. It uses the YAML file to configure the services and enables us to create and start all the services from just one configuration file. | Starting Docker containers using docker-compose: Suppose you have a You can use Navigate to the directory containing the docker-compose.yml file. Start the Docker containers defined in the docker-compose.yml file |
| docker pull | You can download Docker images from the internet. | |
| docker run | It runs a command in a new container, getting the image and starting the container if needed. | |
| git clone | You can create a copy of a specific repository or branch within a repository. | |
| hdfs dfs | Apache Hadoop hadoop fs or hdfs dfs are file system commands to interact with HDFS. These commands are very similar to Unix commands. Hadoop provides two types of commands to interact with the file system: hadoop fs or hdfs dfs. The major difference is that Hadoop commands are supported with multiple file systems like S3, Azure, and many more. | Example-1: Listing files and directories in HDFS: List files and directories in the root directory of HDFS. Example-2: In this example, we use the Sample output: Create a new directory named “mydata” in HDFS. |
| hdfs dfs -cat | Display the contents for a file. | Display the contents of a file in HDFS. |
| hdfs dfs -mkdir | Creates a directory named path in HDFS | Create a directory in HDFS. |
| hdfs dfs -put | Upload a file or folder from the local disk to HDFS. | Upload a file from the local file system to HDFS. |
| LOAD DATA INPATH | Hive provides the functionality to load precreated table entities either from the local file system or from HDFS. This command is used to load data into the hive table. | Load data from HDFS into a Hive table. |
| ls | Writes to standard output the contents of each specified Directory parameter or the name of each specified file parameter, along with any other information you ask for with the flags. If you do not specify a file or directory parameter, the ls command displays the contents of the current directory. | Basic command syntax Example 1: Sorts the file names displayed in the order of last modification time. ‘r’ is for displaying in reverse order Example 2: Displays hidden files |
| mkdir | Used to create one or more directories specified by the Directory parameter. Each new directory contains the standard entries dot (.) and dot dot (..). You can specify the permissions for the new directories with the -m Mode flag. | Create a new directory named “myfolder.” |
| SELECT * FROM | Lists all the rows from the table to check if the data has been loaded from the file. | Select all rows from a table. |
| show tables | Used to see all the tables in the database that have been selected. | Show all tables in the selected database. |
| tar | Looks for archives on the default device (usually tape) unless you specify another device. When writing to an archive, the tar command uses a temporary file (the /tmp/tar* file) and maintains in memory a table of files with several links. | Create a tar archive of a directory. |
| wget | Stands for web get. The wget is a free, noninteractive file downloader command. Noninteractive means it can work in the background when the user is not logged in. | Basic syntax of the wget command; commonly used options are Example 1: Specifies to download file.txt over HTTP website URL into the working directory. Example 2: Specifies to download the archive.zip over the HTTP website URL in the background and returns you to the command prompt in the interim. |