curl -O https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMSkillsNetwork-DB0151EN-edX/labs/FinalProject/movies.jsonSample Data
Import & Query MongoDB
Scenario
You are a data engineer at a data analytics consulting company. Your company prides itself in being able to efficiently handle data in any format on any database on any platform.
- Analysts in your office need to work with data on different databases, and data in different formats.
- While these analysts are good at analyzing data, they count on you to be able to
- move data from external sources into various databases
- move data from one type of database to another
- be able to run basic queries on various databases
Tasks
- Import movies.json into the MongoDB server into an entertainment database and a movie collection.
- Write a MongoDB query to find the year most movies were released.
- Write a MongoDB query to find the count of movies released after the year 1999.
- Write a query to determine the average votes for movies released in 2007.
- Export selected fields from the movies collection into a file named partial_data.csv.
Steps
Download Data
- Download data movies.json into the could IDE directory
- Here is a view of a sample movie document
{
_id: '9',
title: 'The Lost City of Z',
genre: 'Action,Adventure,Biography',
Description: 'A true-life drama, centering on British explorer Col. Percival Fawcett, who disappeared while searching for a mysterious city in the Amazon in the 1920s.',
Director: 'James Gray',
Actors: 'Charlie Hunnam, Robert Pattinson, Sienna Miller, Tom Holland',
year: 2016,
'Runtime (Minutes)': 141,
rating: 'unrated',
Votes: 7188,
'Revenue (Millions)': 8.01,
Metascore: 78
}Import Data
- Import movies.json into MongoDB
- named: entertainment and use
- collection named: movies
~$ mongoimport -u root -p HkbscmpId8EaS12seIqEIGUw --authenticationDatabase admin -d entertainment -c movies --host mongo movies.json
2024-10-25T12:18:22.642-0400 connected to: mongodb://mongo/
2024-10-25T12:18:22.665-0400 100 document(s) imported successfully. 0 document(s) failed to import.
- The step above imported the file and created a db and collection
- Let’s go into the Mongo Server and list all DBs present
List DBs
- Either use the Mongo CLI to connect to the server or use the code below in Connect to Mongo
show dbs
Connect to DB
use entertainment
Query 1
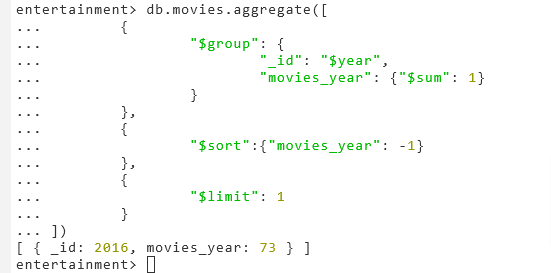
Find the year in which most number of movies were released
- So basically we can use
groupto croup documents by a certain field: release year - Calculate the total count within each year using $sum aggregation
- Sort the years in descending order
- Limit the output to 1 document the first year in the filtered output, which would have the largest count
~$ mongosh -u root -p SUBSTITUTE PASSWORD HERE --authenticationDatabase admin local --host mongo
local 64.00 KiB
training 8.00 KiB
scmpId8EaS12seIqEIGUw@172.21.65.104:27017ongosh mongodb://root:Hkbs
Current Mongosh Log ID: 671bca4d5b8ffc372cfe6910
Connecting to: mongodb://<credentials>@172.21.65.104:27017/?directConnection=true&appName=mongosh+2.3.2
Using MongoDB: 3.6.3
Using Mongosh: 2.3.2
For mongosh info see: https://www.mongodb.com/docs/mongodb-shell/
------
The server generated these startup warnings when booting
2024-10-25T15:46:40.609+0000:
2024-10-25T15:46:40.609+0000: ** WARNING: Using the XFS filesystem is strongly recommended with the WiredTiger storage engine
2024-10-25T15:46:40.609+0000: ** See http://dochub.mongodb.org/core/prodnotes-filesystem
------
# List ALL DBs
test> show dbs
admin 80.00 KiB
config 12.00 KiB
entertainment 60.00 KiB
local 64.00 KiB
training 8.00 KiB
# Connect to db
test> use entertainment
switched to db entertainment
# Query db
# We first group by year and sum all the movies per year
db.movies.aggregate([
{
"$group": {
"_id": "$year",
"movies_year": {"$sum": 1}
}
},
# Here we sort in descending order
{
"$sort":{"movies_year": -1}
},
# Limit/Filter the output to the largest count
{
"$limit": 1
}
])Query 2
Find the count of movies released after 1999
Greater
- use
$gtto find a value greater than
Count Documents
- To find the count of documents use
db.xxx.countDocuments()
entertainment> db.movies.countDocuments({ year: {$gt : 1999} })
99
Query 3
Find the average votes for movies released in 2007
Match
- We filter for only year 2007 by using
match
Average
- Here we average what was filtered using
$avg
entertainment> db.movies.aggregate([
{ $match: { year: 2007}},
{ $group: { _id: "$year", averageVotes: { $avg: "$Votes" }} }
])
# OUTPUT
[ { _id: 2007, averageVotes: 192.5 } ]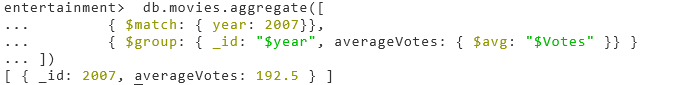
Export
Export the fields:
id, title, year, rating, directoryfrom the movies collection to a file named partial_data.csv
Export to csv
- use
mongoexport
~$ mongoexport -u root -p HkbscmpId8EaS12seIqEIGUw --authenticationDatabase admin -d entertainment -c movies -f "_id,title,year,rating,director" --type=csv -o partial_data.csv --host mongo
Create Instance
- save user: root
- save pasw: HkbscmpId8EaS12seIqEIGUw
- Open new terminal
- Connect to MongoDB server using code
- Or simply click on the MongoDB CLI
Connect to Mongo
- This command will either connect to the DB training if it exists or
- creates a db if doesn’t exist
use training
Create Collection
- Let’s create a collection
db.createCollection("bigdata")
# Connect to MongoDB server or use CLI button
~$ mongosh -u root -p SUBSTITUTE PASSWORD HERE --authenticationDatabase admin local --host mongo
# OUTPUT
Current Mongosh Log ID: 671bbeea871cb6afc3fe6910
Connecting to: mongodb://<credentials>@mongo:27017/local?directConnection=true&authSource=admin&appName=mongosh+2.3.2
Using MongoDB: 3.6.3
Using Mongosh: 2.3.2
For mongosh info see: https://www.mongodb.com/docs/mongodb-shell/
To help improve our products, anonymous usage data is collected and sent to MongoDB periodically (https://www.mongodb.com/legal/privacy-policy).
You can opt-out by running the disableTelemetry() command.
------
The server generated these startup warnings when booting
2024-10-25T14:13:41.675+0000:
2024-10-25T14:13:41.675+0000: ** WARNING: Using the XFS filesystem is strongly recommended with the WiredTiger storage engine
2024-10-25T14:13:41.675+0000: ** See http://dochub.mongodb.org/core/prodnotes-filesystem
------
local>
# Connect to db
local> use training
switched to db training
# Create Collection
training> db.createCollection("bigdata")
{ ok: 1 }Cassandra1
Tasks
- Create a keyspace named entertainment.
- Import partial_data.csv into a Cassandra server.
- Write a CQL query to count the movie table’s rows.
- Create an index for the movie table’s rating column using CQL.
- Write a CQL query to count the number of movies that are rated “G.”
Create Instance
- Click on Open Cassandra Page in IDE
- Open Cassandra CLI
- save host: 127.xxx Port: 9042
- Save user: emhrcf psw: MTA2NzItZW1ocmNm
Connect to Cassandra Server
- use this code: cqlsh HOST PORT –username root –password
# Connect to Cassandra server with the code below or use CLI button
~$ cqlsh 172.21.27.155 9042 --username root --password ZmfV6DfM4ZEQs5pktwVDWSR7
# OUTPUT
WARNING: cqlsh was built against 4.0.14, but this server is 5.0. All features may not work!
Connected to Test Cluster at 172.21.82.211:9042
[cqlsh 6.0.0 | Cassandra 5.0-beta1 | CQL spec 3.4.7 | Native protocol v5]
Use HELP for help.
root@cqlsh> Download Data
- We will use the data we exported from MongoDB
- If didn’t do step above use the code below to download partial_data.csv into Cassandra Server
curl -O https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMSkillsNetwork-DB0151EN-edX/labs/FinalProject/partial_data.csvCreate Keyspace
- create keyspace: entertainment
- without specifying any replication factors or strategy
Assess Keyspace
- Review keyspace
CREATE KEYSPACE entertainment
WITH replication = {'class':'SimpleStrategy', 'replication_factor' : 3};
Warnings :
Your replication factor 3 for keyspace entertainment is higher than the number of nodes 1
root@cqlsh> describe keyspaces
entertainment system_auth system_schema system_views
system system_distributed system_traces system_virtual_schema
Import Data
Import partial_data.csv into Cassandra
- Import file into a keyspace named entertainment and
- table named movies use
CREATE TABLE() - First we’ll create a table: configure all the columns including the id column
- _id
- title
- year
- rating
- director
- View details of table with
describe - Import the data into the table using
COPY
root@cqlsh> use entertainment;
root@cqlsh:entertainment> CREATE TABLE movies (
... id text PRIMARY KEY,
... title text,
... year text,
... rating text,
... director text
... );
root@cqlsh:entertainment> describe movies
CREATE TABLE entertainment.movies (
id text PRIMARY KEY,
director text,
rating text,
title text,
year text
) WITH additional_write_policy = '99p'
AND allow_auto_snapshot = true
AND bloom_filter_fp_chance = 0.01
AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'}
AND cdc = false
AND comment = ''
AND compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy', 'max_threshold': '32', 'min_threshold': '4'}
AND compression = {'chunk_length_in_kb': '16', 'class': 'org.apache.cassandra.io.compress.LZ4Compressor'}
AND memtable = 'default'
AND crc_check_chance = 1.0
AND default_time_to_live = 0
AND extensions = {}
AND gc_grace_seconds = 864000
AND incremental_backups = true
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair = 'BLOCKING'
AND speculative_retry = '99p';
# Copy data into Table
root@cqlsh:entertainment> COPY entertainment.movies(id,title,year,rating,director) FROM '/home/project/partial_data.csv' WITH DELIMITER=',' AND HEADER=TRUE;
# OUTPUT
Using 15 child processes
Starting copy of entertainment.movies with columns [id, title, year, rating, director].
Processed: 100 rows; Rate: 77 rows/s; Avg. rate: 129 rows/s
100 rows imported from 1 files in 0.774 seconds (0 skipped).
Query 1
Count the number of rows in table movies
# Count number of rows in table
root@cqlsh:entertainment> select count(*) from movies;
count
-------
100
(1 rows)
Create Index
Create an index for the rating column in the table movies
- use
CREATE INDEXto Create the index then - Use
describeon movies to show the specifics of the table
root@cqlsh:entertainment>CREATE INDEX IF NOT EXISTS rating_index
ON entertainment.movies (rating);
# Display the details of movies
root@cqlsh:entertainment> describe movies
CREATE TABLE entertainment.movies (
id text PRIMARY KEY,
director text,
rating text,
title text,
year text
) WITH additional_write_policy = '99p'
AND allow_auto_snapshot = true
AND bloom_filter_fp_chance = 0.01
AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'}
AND cdc = false
AND comment = ''
AND compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy', 'max_threshold': '32', 'min_threshold': '4'}
AND compression = {'chunk_length_in_kb': '16', 'class': 'org.apache.cassandra.io.compress.LZ4Compressor'}
AND memtable = 'default'
AND crc_check_chance = 1.0
AND default_time_to_live = 0
AND extensions = {}
AND gc_grace_seconds = 864000
AND incremental_backups = true
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair = 'BLOCKING'
AND speculative_retry = '99p';
CREATE INDEX rating_index ON entertainment.movies (rating);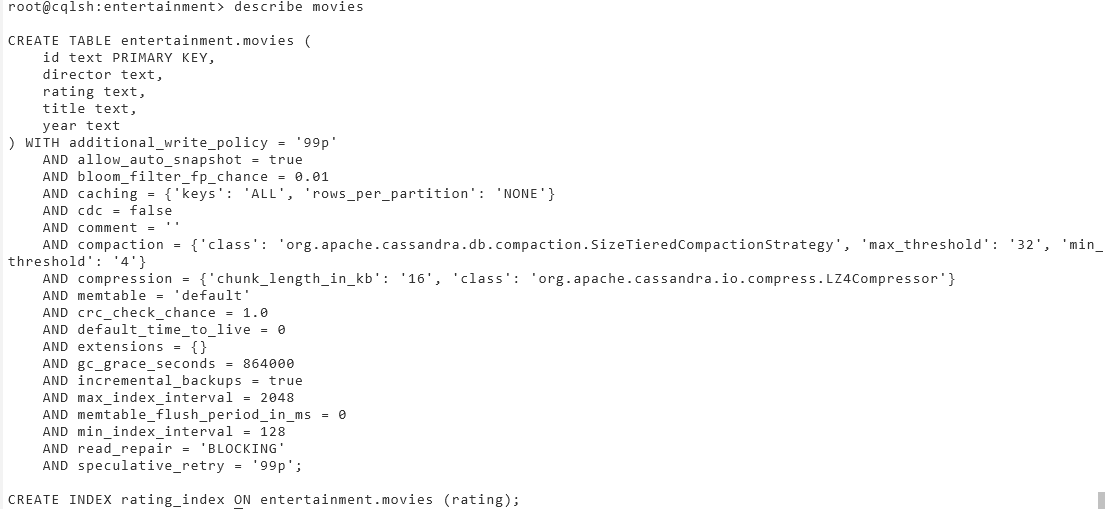
Query 2
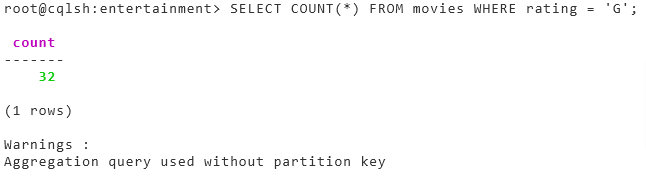
Count the number of movies that are rated “G”
- We will use
SELECTandCOUNT(*)along with WHEREstatement
root@cqlsh:entertainment> SELECT COUNT(*) FROM movies WHERE rating = 'G';
count
-------
32
(1 rows)
Warnings :
Aggregation query used without partition key