# Select/create a db
test> use training
switched to db training
# Create a collection
training> db.createCollection("bigdata")
{ ok: 1 }
# Insert documents
training> use training
for (i=1;i<=200000;i++){print(i);db.bigdata.insert({"account_no":i,"balance":Math.round(Math.random()*1000000)})}
# Count of documents inserted
training> db.bigdata.countDocuments()
200000
# Let's time a query: the details of account number 58982
training> db.bigdata.find({"account_no":58982}).explain("executionStats").executionStats.executionTimeMillis
57
# Create an index on the field account_no
training> db.bigdata.createIndex({"account_no":1})
account_no_1
# List all the indexes in the db
training> db.bigdata.getIndexes()
[
{ v: 2, key: { _id: 1 }, name: '_id_', ns: 'training.bigdata' },
{
v: 2,
key: { account_no: 1 },
name: 'account_no_1',
ns: 'training.bigdata'
}
]
# Run a Query to test the time consumed
training> db.bigdata.find({"account_no": 69271}).explain("executionStats").executionStats.executionTimeMillis
0
# Delete the index we created above
training> db.bigdata.dropIndex({"account_no":1})
{ nIndexesWas: 2, ok: 1 }Create an Index
Indexes
Indexes help quickly locate data without looking for it everywhere.
Indexing the fields that are frequently queried or used for sorting helps to improve query execution times. However, ensuring that the queries support appropriate indexes and avoid creating extra indexes is vital. This helps to impact the right performance and save storage space. Also, keep in mind that indexing is a continuous process; however, queries need to be monitored and updated based on the business requirements.
For example:
Until just a few years ago, telephone books were really popular. All the names were indexed by surname and first name. So, to find one person, you jump into their surname section. D for Doe, then you go to first names starting with J , and you can easily find John Doe.
Instead of scanning the whole collection, we create an index on the field ‘courseId’ in the course enrollment collection. ‘courseId : 1’ means store the index in ascending order.
Our index on ‘courseId’ will help find those documents more efficiently. But to organize the students by ‘studentId’ in ascending order, MongoDB will need to perform in-memory sort, which will not be efficient.
In this situation, we can change our index to be a compound index, which means indexing more than one field. Because the items in the index are organized in ascending order, once we find all documents with a matching ‘courseId’ of ‘1547’, they will all be already sorted by ‘studentId’ because of this index.
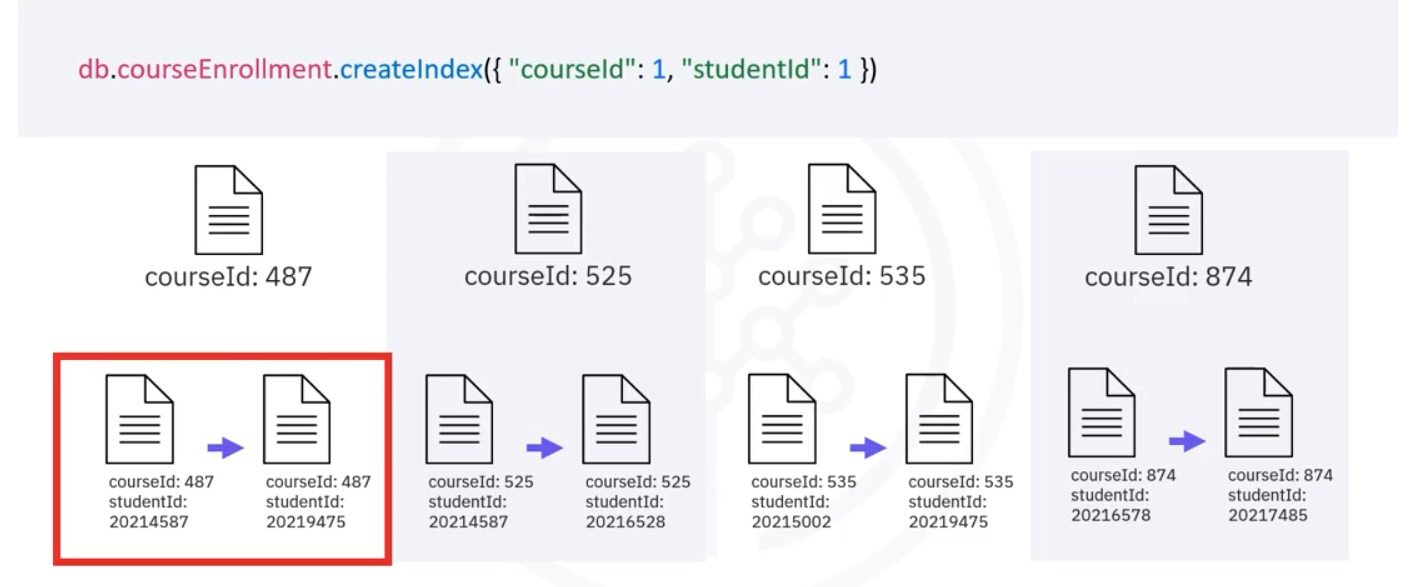
- Indexes in MongoDB are special data structures. They store the fields you are indexing, and a location where that document is stored on disk.
- MongoDB stores indexes in a tree form: a balanced tree to be precise.
- Imagine our last example: ‘courseId,’ being the first field in our compound index, is in ascending order.
- Under each tree node, you will have students in ascending order too.
- This makes finding documents much more efficient, whether it’s an equality or a range search.
- And if you are sorting on a field which is already indexed, MongoDB doesn’t need to sort it again.
Create Instance
- I’ll be using MongoDB on the cloud
- So we start by opening the MongoDB page in IDE
- Create an instance
Select DB
- We’ll be using the same db training that we created in the earlier examples
Create a Collection
- Create a new collection bigdata
Insert Document
- The code given below will insert 200000 documents into the ‘bigdata’ collection.
- Each document would have a field named account_no which is a simple auto increment number.
- And a field named balance which is a randomly generated number, to simulate the bank balance for the account
Count # of Documents
- Let’s verify the number of documents inserted
db.bigdata.countDocuments()
Time a Query
- Let us run a query and find out how much time it takes to complete.
- Let us query for the details of account number 58982
- We will make use of the explain function to find the time taken to run the query in milliseconds.
db.bigdata.find({"account_no":58982}).explain("executionStats").executionStats.executionTimeMillis
- Before you create an index, choose the field you wish to create an index on.
- It is usually the field that you query most
- Create an index on the field account_no.
db.bigdata.createIndex({"account_no":1})
List all the indexes
db.bigdata.getIndexes()
Time a Query
- Let us run a similar query and find out how much time it takes to complete.
- Let us query for the details of account number 69271
- We will make use of the explain function to find the time taken to run the query in milliseconds.
db.bigdata.find({"account_no": 69271}).explain("executionStats").executionStats.executionTimeMillis
Delete an Index
- Let’s delete the index we created above
db.bigdata.dropIndex({"account_no":1})