Before we get into the specifics let’s get some definitions out of the way:
Definitions

One of the biggest and most striking differences between relational database management systems and NoSQL databases is their data consistency models.
The two most common consistency models that are known and in use nowadays are ACID and BASE:
- Relational databases use the ACID model,
- Generally, NoSQL databases use the BASE model
For example, MongoDB, which is a document based NoSQL database started supporting ACID transactions from Version 4.0. They both have their pros and cons:
ACID
This term is an acronym for Atomicity, Consistency, Isolation, and Durability, which is a set of properties that guarantee reliable processing of database transactions in traditional relational databases.
Many developers are familiar with ACID transactions from working with relational databases. As such, the ACID consistency model has been the norm for some time.
The ACID consistency model ensures that a performed transaction is always consistent. This makes the ACID consistency model a good fit for businesses that deal with online transaction processing, such as financial institutions or data warehousing types of applications.
These organizations need database systems that can handle many small simultaneous transactions like relational databases can. An ACID system provides a consistent model you can count on for the structural integrity of your data.
Use Cases: While there are many use cases for ACID databases, one stands out.
- Financial institutions will almost exclusively use ACID databases for their money transfers because these operations depend on the atomic nature of ACID transactions. Uninterrupted transaction that is not immediately removed from the database can cause serious complications. Money could be debited from one account and due to an error never credited to the other, or not credited at all.
Atomic
In the context of database transactions, atomic means that an operation is indivisible and either completes fully or is completely rolled back. It ensures that the database remains in a consistent state. All operations in a transaction succeed, or every operation is rolled back.
Consistent
On the completion of a transaction, the structural integrity of the data in the database is not compromised.
Isolated
Transactions cannot compromise the integrity of other transactions by interacting with them while they are still in progress.
Durable
The data related to the completed transaction will persist, even in the case of network or power outages. If a transaction fails, it will not impact the already changed data.
BASE
In the NoSQL database world, ACID transactions are less fashionable because some databases have loosened the requirements for immediate consistency, data freshness, and accuracy. They do this to gain other benefits, such as availability, scale, and resilience.
The BASE data store values availability over consistency, but it doesn’t offer a guaranteed consistency of replicated data at right times. NoSQL databases use the BASE consistency model.
Essentially, the BASE consistency model provides high availability.
Basically Available
The BASE acronym stands for basically available. Rather than enforcing immediate consistency BASE modeled NoSQL databases will ensure the availability of data by spreading and replicating it across the nodes of the database cluster.
Soft State
Due to the lack of immediate consistency, data values may change over time.
In the BASE model, data stores don’t have to be right consistent nor do different replicas have to be mutually consistent all the time.
Eventually Consistent
The fact that the BASE model does not enforce immediate consistency does not mean that it never achieves it. However, until it does, data reads might be inconsistent.
Use Cases: The BASE consistency model is used by
- Marketing and customer service companies that deal with sentiment analysis and social network research.
- Social media applications that contain vast amounts of data and need to be always available, and worldwide online services like Netflix, Spotify, and Uber.
- The fame of BASE databases increased because well known worldwide online services such as Netflix, Apple, Spotify, and Uber use BASE data stores for applications like user profile data storage.
A common characteristic of these services is that they must always be accessible, no matter which part of the world users are located. If a part of their database cluster becomes unavailable, the system needs to be able to serve the user requests without any disruptions.
Distributed Databases
A distributed database is a collection of multiple interconnected databases, which are spread physically across various locations that communicate via a computer network.
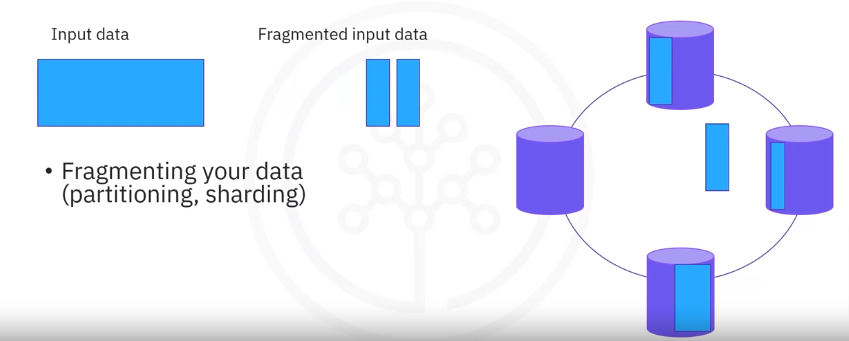
- A distributed database is physically distributed across the data sites by fragmenting and replicating the data.
- A distributed database follows the BASE consistency model.
Fragmentation
To store a large piece of data on all servers of a distributed system, you need to break your data into smaller pieces. This process, also known as
- fragmentation of data
- also called partitioning of data or
- sharding of data by some known SQL databases,
This process is usually done by the key of the key value record in two ways.
- By either grouping all keys lexically. For example, all keys that start with A or between A and C can be found on a specific server,
- or by grouping all records that have the same key and placing them on the same server. For example, all transactions from a store where store ID is the key of the records. In this way with a query like give me all sales from a store, all records will be on a single server.
Replication
Now that data is distributed to all the clusters nodes, how do we make sure that if a node fails we don’t lose all of the data in that node? This is done through replication, where
- all fragments or partitions or shards of your data are stored redundantly in two or more sites
- Hence, in replication, systems maintain copies of data.
- Replication increases the availability of data in different sites
- If one node fails, that piece of data can be retrieved from another node.
Synchronization
However, it has certain disadvantages as well. Data needs to be consistently synchronized. Any change made at one site needs to be replicated to every site where that related data is stored, or else it will lead to inconsistency.
Reliability & Availability
Distributed systems have numerous advantages.
- They allow more reliability and availability.
- The data is replicated at multiple sites. If the local server is unavailable, the data can be retrieved from another available server.
Improved Performance
Another advantage of distributed databases is improved performance. Especially for high volumes of data,
- query processing time is reduced, which also helps improve performance.
- You can easily grow or scale to increase your system capacity just by adding new servers to the cluster.
Continuous Availability
Distributed systems also provide continuous operation with no more reliance on the central site.
Disadvantages
But their architecture also introduces some challenges.
- Concurrency control. Because the same piece of data is stored in multiple locations if you modify, update, or delete your data, how can data synchronization be secured?
- To solve this issue, some distributed databases direct READ/WRITES operations for a certain fragment of data to only one node, leaving the cluster to synchronize with the other nodes.
- WRITE operations go to all nodes holding that particular fragment of data and READS to a subset of nodes as required per consistency.
- In both cases, the developer can control the consistency of the operation or how many nodes need to answer for a certain operation to be considered successful.
- Due to concurrency control issues distributed databases by design don’t really support transactions or provide a very limited version of them.
Distributed databases might be inconsistent at times, but eventually, consistency can be achieved.
Migrating from RDBMS to NoSQL
In reality, RDBMS and NoSQL databases are not competing because they cater to quite different requirements and use cases. While it is possible to migrate from an RDBMS system to a NoSQL system, this should be done based on the characteristics required by your end solution.
The change might be driven by additional performance or flexibility, whatever your reasons are, you need to analyze them against what NoSQL can do for you.
RDBMS vs NoSQL

RDBMS
- If you need full consistency for your data,
- if your data is structured
- If you need multi-document transactions and
- complicated joins
NoSQL
- if you have loads of data and need a high performance system
- If your data is unstructured and could benefit from a flexible schema,
- if your system needs to be available and
- scalable
RDBMS & NoSQL
There might be other cases in which both relational and NoSQL databases will be needed
- If you have too much data and need performance and need to scale fast
- But at the same time you also need transactions support and
- complex joins on your data than you might think of a combined solution.
RDBMS -> NoSQL
- In RDBMS, the solution design starts from the data, the entities and their relationship.
- In NoSQL, it’s not the data that drives your data model or schema, it’s the way your application accesses the data and the queries you are going to make. Your data model is driven by your queries, not the data itself
- In NoSQL models should be based on how the app interacts with the data rather than how the model can be stored as rows in one or more tables.
- In RDBMS, data is normalized while in NoSQL it is denormalized.
- With NoSQL, starting from your query means that you will structure your data on disk accordingly. Thus, you may need to store the same data in different models just to answer the question, and this will lead to data denormalization. While data in RDBMS is normalized, you need to be open to the situation in which you start with your queries instead of your data.
- From ACID to BASE, you need to understand that sometimes services require availability more than consistency when both availability and performance are needed. Thus, distributed systems consistency cannot be ensured.
- Remember cap theorem, many of today’s online services value availability more than consistency. And because of this they look for systems that can provide it, taking into consideration the amount of data they are dealing with and their geographical presence.
- NoSQL databases, are not designed to support transactions or joins or complex processing except in limited cases.
Summary
| ACID | An acronym for Atomicity, Consistency, Isolation, and Durability, which is a set of properties that guarantee reliable processing of database transactions in traditional relational databases. |
| BASE | An alternative to ACID. Stands for basically available, soft state, eventually consistent. BASE allows for greater system availability and scalability, sacrificing strict consistency in favor of performance. |
| Bigtable | A NoSQL database system developed by Google, designed for handling large amounts of data and providing high performance, scalability, and fault tolerance. |
| Caching | The temporary storage of frequently accessed data in high-speed memory reduces the need to fetch the data from the primary storage, which can significantly improve response times. |
| Cluster | A group of interconnected servers or nodes that work together to store and manage data in a NoSQL database, providing high availability and fault tolerance. |
| Column database | A NoSQL database model that stores data in column families rather than tables, making it suitable for storing and querying vast amounts of data with high scalability. Examples include Apache Cassandra and HBase. |
| CRUD | CRUD is an acronym for create, read, update, and delete, which are the basic operations for the basic operations for interacting with and manipulating data in a database. |
| DBaaS | This acronym stands for database as a service, a cloud-based service that provides managed database hosting, maintenance, and scalability, allowing users to focus on application development without managing the database infrastructure. |
| Document | A NoSQL database model that stores data in semi-structured documents, often in formats like JSON or BSON. These documents can vary in structure and are typically grouped within collections. |
| Graph database | A NoSQL database model optimized for storing and querying data with complex relationships, represented as nodes and edges. Examples include Neo4j and OrientDB. |
| Horizontal scaling | The process of adding more machines or nodes to a NoSQL database to improve its performance and capacity. This is typically achieved through techniques like sharding. |
| Indexing | The creation of data structures that improve query performance by allowing the database to quickly locate specific records based on certain fields or columns. |
| JSON | JSON is an acronym for JavaScript Object Notation, a lightweight data-interchange format used in NoSQL databases and other data systems. JSON is human-readable and easy for machines to parse. |
| Key-value | A NoSQL database model that stores data as key-value pairs. It’s a simple and efficient way to store and retrieve data where each key is associated with a value. |
| Normalized | A database design practice where data is organized to minimize redundancy and maintain data integrity by breaking it into separate tables and forming relationships between them. |
| NoSQL | NoSQL stands for “not only SQL.” A type of database that provides storage and retrieval of data that is modeled in ways other than the traditional relational tabular databases. |
| Sharding | Refers to the practice of partitioning a database into smaller, more manageable pieces called shards to distribute data across multiple servers. Sharding helps with horizontal scaling. |
| TTL | Stands for “Time to Live,” which is a setting in NoSQL databases that determines how long a piece of data should be retained before it’s automatically removed from the database. |
| XML | Stands for Extensible Markup Language, another data interchange format used in some NoSQL databases. It’s also human-readable and can represent structured data. |
| Term | Definition |
|---|---|
| Availability | In the context of CAP, availability means that the distributed system remains operational and responsive, even in the presence of failures or network partitions. Availablity is a fundamental aspect of distributed systems.. |
| Basically available | A basically available system remains operational even in the presence of failures or faults. |
| CAP | CAP is a theorem that highlights the trade-offs in distributed systems, including NoSQL databases. CAP theorem states that in the event of a network partition (P), a distributed system can choose to prioritize either consistency (C) or availability (A). Achieving both consistency and availability simultaneously during network partitions is challenging. |
| Consistency | In the context of CAP, consistency refers to the guarantee that all nodes in a distributed system have the same data at the same time. |
| Consistent | The action of being consistent ensures that a database transaction transforms the database from one consistent state to another. |
| Denormalized | Denormalization is a database design technique used in NoSQL databases (and sometimes in traditional relational databases) where redundant or duplicate data is intentionally introduced into one or more tables to improve query performance and reduce the need for complex joins. |
| Durable | Guarantees that once a transaction is committed, its changes are permanent and will survive any system failures. |
| Eventually consistent | An eventually consistent system reaches a consistent state, where all nodes have the same data given that there are no new updates. |
| Isolated | Isolation refers to the property that multiple transactions can run concurrently without affecting each other. |
| Joins | Combining data from two or more database tables based on a related column between them. |
| Normalized | A database design practice where data is organized to minimize redundancy and maintain data integrity by breaking it into separate tables and forming relationships between them. |
| Partition tolerance | In the context of CAP, partition tolerance is the ability of a distributed system to continue functioning even when network partitions or communication failures occur. |
| Replication | Replication involves creating and maintaining copies of data on multiple nodes to ensure data availability, reduce data loss, fault tolerance (improve system resilience), and provide read scalability. |
| Sharding | Refers to the practice of partitioning a database into smaller, more manageable pieces called shards to distribute data across multiple servers. Sharding helps with horizontal scaling. |
| Soft state | A soft state acknowledges that the system’s state might be transiently inconsistent due to factors like network partitions or concurrent updates. And it’s willing to accept a certain level of inconsistency or uncertainty in the data temporarily. |
| Transactions | Transactions are sequences of database operations (such as reading and writing data) that are treated as a single, indivisible unit. |