{
"firstName":"John",
"lastName":"Doe".
"email":"..",
"studentID": 2027418
}MongoDB Overview
Definition
MongoDB is a document and a NoSQL database. Instead of storing data in tables of rows or columns like SQL databases, each record in a MongoDB database is a document, and you store the data in a non relational way.
- Documents are associative arrays like JSON objects or Python dictionaries.
- MongoDB documents of similar type are grouped into a collection. Our Campus Management system stores all student records or documents in the student’s collection, and similarly all staff documents are stored in the employees collection.
- Let’s dissect our document:
- In the document above, first name, last name, email, and student ID are fields or properties with values representing a student named John Doe,
- and each field name is unique within that document
- MongoDB supports a variety of data types, so you have the full capability to use the correct data type to store your information in.
- For example, dates should be stored as ISODate or Unix-style epic dates, which will help you with queries like, give me all students born between 15th January to 15th February.
- Numbers can be stored either as whole numbers or decimals.
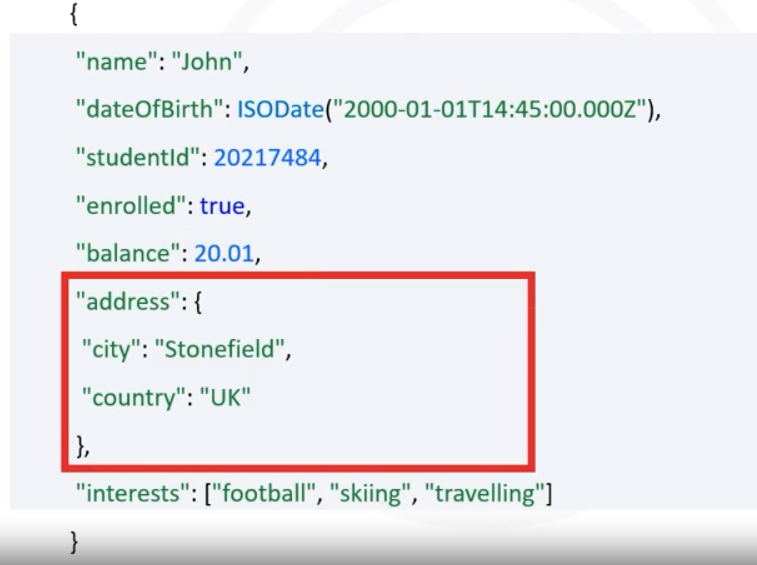
- Being a document database, MongoDB also allows you to store subdocuments to group secondary information together. As you see in the image below: “address”
Why use MongoDB
- It also supports lists of values, not just text, (as you see in “interests” above) but even different kinds mixed together.

- Flexibility of Schema: Traditional relational databases required you to create the schema first, then create table structures that will hold your data. So, if you decide to store an additional field, you will then have to alter your tables.
- Compare the two addresses shown above. There is no zip code for UK addresses and no post code for American addresses. In a relational world where fields names must be present in each row, this would cause us to have either overarching fields or a lot of fields with no values. But storing in this format in MongoDB is not a problem because it allows us this flexibility with the schema.
- In MongoDB, you change as you go along. MongoDB also gives you the power to bring in any structured or unstructured data.
- It also provides high availability by keeping multiple copies of your data:
- MongoDB natively supports being a highly available system bymeans of redundancy.
- Typical MongoDB setups are three-node replica sets where one of them is a primary member and the others are secondary members.
- Replication keeps a copy of your data on other data-bearing nodesin the cluster.
- If one system fails, the other one takes overand you do not see any downtime.
- This also works for system maintenance situations where you might take away a node from making updates to software, operating systems, file systems, security patches, or your MongoDB version.
- You can design complex data structures easily in MongoDB without worrying about the complexity of how it is stored and how it should be linked.
- Querying and analytics capabilities. Mongo Query Language or MQL has a number of operators that you can use to build fairly complex queries to find your data. If your queries are even more complex, you can use aggregation pipelines within MongoDB.
- Scalability provided by MongoDB means as your data needs grow, you can easily scale vertically by introducing bigger, faster, better hardware,or horizontally by partitioning your data.
- All of that can be done whether you are running a self-managed on-premises MongoDB or the hybrid or cloud-hosted and fully managed services such as IBM Cloud databases for MongoDB or MongoDB Atlas on AWS, Azure, and Google Cloud.

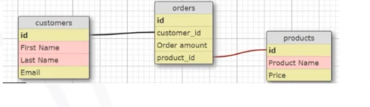
Code-first Approach: Shown below is a RDBMS schema, Relational databases add complexity when you start because first you need to create your table design and only then are you allowed to work on your database. Since Mongo DB works on documents, it means
- you can access your data without having any complexity in between
- There are no complex table definitions
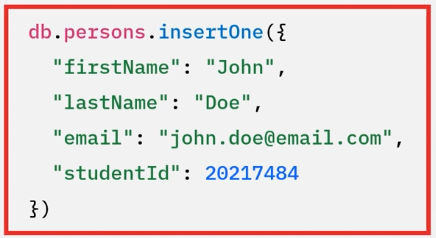
- You can start writing your first data as soon as you connect to your MongoDB database as you see here below
- Let’s look at an example of a stock market aggregator shown below:
- This collects stock data from different sources.
- Each piece of source data can be a different shape, which means it’s essentially unstructured data when it comes to MongoDB. With the flexibility MongoDB provides, we can store all this data together in one collection.

Use Cases
One View
MongoDB allows you to bring data from different sources into it. So instead of each part of your data living in silos, You can ingest multiple shapes and formats of data into MongoDB. To get one view of it, put together.
This is helped by the flexible schema supported by MongoDB.
IoT
MongoDB can be used with IoT devices.
- There are billions of IoT devices around the globe. These include small components in your autonomous car to an Internet-connected light bulb.
- These devices generate vast amounts of data.
- Scaling capabilities, MongoDB can easily store all of this data distributed globally.
- And once it is in MongoDB, using the expressive querying capabilities, all of this data can be used in complex analysis and decision making.
E-Commerce
MongoDB can also be used with e-commerce solutions.
- Products sold on an e-commerce website have different attributes. For example,
- a phone has attributes such as storage, network, and color
- a book will have attributes such as publisher, writer, and number of pages
- Products also have attributes such as top reviews, pricing, inventory, and other metadata.
- Optimized for READ - With the help of documents, sub-documents, and list properties in MongoDB, you can store the information together so it is optimized for reads.
- A perfect fit for use cases allowing dynamic schema.
Real-time Analytics
MongoDB is a good fit when you want real-time analytics. Most organizations want to make better decisions based on their data. Doing historical analysis is easy, but only a few can
- respond to changes happening minute by minute
- due to complex Extract, Transform, and Load (or ETL) processes.
- With MongoDB, you can do most of the analysis where the data is stored.
- That data can be semi-structured or completely unstructured.
- All of this can be done in real time.
Gaming
MongoDB has a part to play in the gaming world, too.
- With more than ever multiplayer games being played globally, getting the data across is hugely important. With native scalability, also known as Sharding, MongoDB makes it easier to reach users around the world.
- And again, with the flexible schema it is easier to support ever-changing data needs.
- No downtime
- Supports rapid development
Finance Industry
MongoDB has usage scenarios in the finance industry too.
- Speed: Nowadays, we want our banking transactions to be as quick as possible
- Security: we alsoexpect the financial industry to keep our information secure. With MongoDB, you can perform thousands of operations on your database per second.
- Security: all the information is encrypted while in transfer and when stored on disk. You can additionally encrypt individual fields to avoid any data incidents.
- Reliability: like every industry, financial institutions have much higher requirements for reliability and services being available around the clock. We expect our finances to be available without any downtime. This makes MongoDB a good choice for banks, trading companies, and the financial industry in general.
Replication
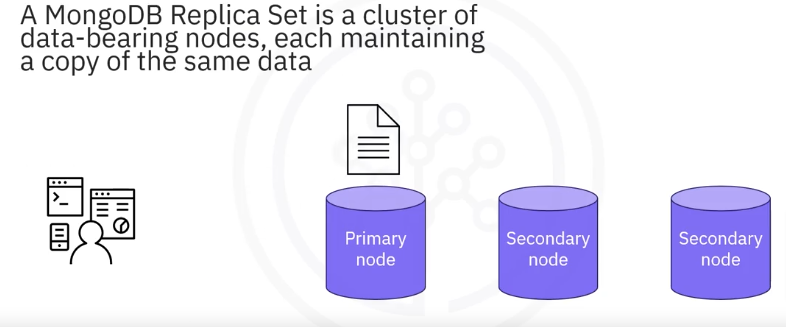
A typical MongoDB cluster is made of three data-bearing nodes. All three nodes have the same data, hence the name Replica Set. Data is written to the primary node which then gets replicated to the secondary nodes.
- Having multiple copies of the data means that replication creates redundancy. So if one piece of server hardware fails, you still have multiple copies of the data.
- This capability provides you with a highly available database during such failures or plan maintenance periods. Such planned maintenance should be done in a rolling fashion, taking one node out for operating system, security, hardware, or software updates, or for upgrading MongoDB itself.
A common misconception about replication is that replication can save you from disasters, such as accidentally deleting your database. Because the database is a replica set, what happens on the primary node is replicated on the secondary nodes. For disaster recovery scenarios, you’ll rely on backups and restoration processes.
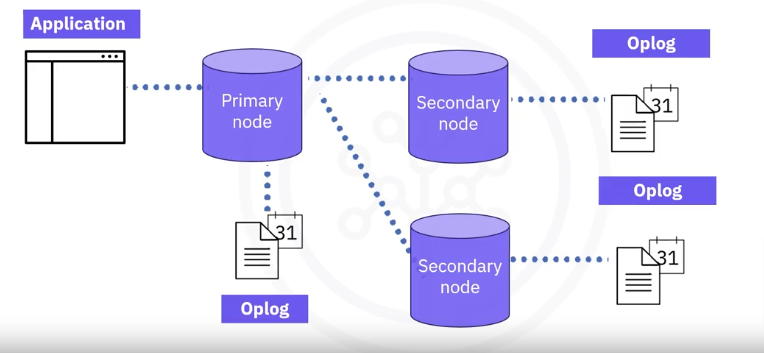
Here’s an overview of the MongoDB replication process:
- The application writes changes to the primary node.
- The primary node records those changes including timestamps in its operations log known as the Oplog.
- All of the other data-bearing nodes, the secondary nodes, observe the primary node Oplog for new changes.
- The secondary nodes copy and apply the new changes by first recording those changes in their respective Oplogs with the time stamp that indicates when they receive the change and reference the primary Oplog timestamps to record only the most recent changes.
Sharding
When you need to store even more data or you want to improve your read and write performance, naturally, you will invest in bigger and faster hardware to increase capacity, but sometimes that is not feasible. In those situations, you can scale horizontally by implementing sharding,
which is the partitioning of your biggest collections.
Scaling horizontally is one of the key points of MongoDB.
- Sharding helps distribute data across servers or shards to handle large volumes of data and high throughput workloads.
- However, consider the scalability requirements and plans for early sharding when designing MongoDB deployment.
- Further, select an appropriate shard key to distribute data equally across the shards by regularly monitoring their distribution and performance based on application growth. Preventing unauthorized access
Databases often contain valuable and sensitive information, such as personal data, financial records, intellectual property, and proprietary business information. To achieve this, follow security best practices such as enabling authentication, using role-based access control (RBAC) to define user permissions, and configuring network encryption with transport layer security/secure sockets layer (TLS/SSL). Regularly update MongoDB to the latest version to patch security vulnerabilities and maintain a robust security posture.
Benefits
Sharding your biggest or most demanding collections has many benefits
- You increase your throughput by directing your queries only to relevant shards
- You can also store more data which previously you couldn’t fit on a single node
- You can also split data across shards based on regions: Data for US customers will only live on shards running in the US, while European customers have their data on European base shards. This can help you adhere to legal requirements.
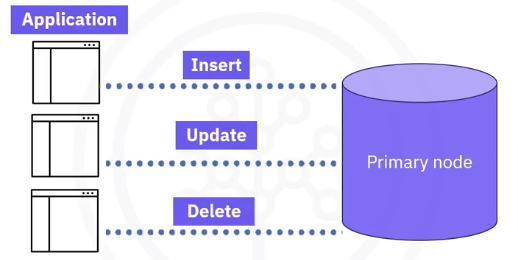
- As a global application, you get one view of your database to manage. The primary node is the only node that can accept right operations including inserts, updates, and deletes from client applications.
Election
An election is the process of selecting a new primary node. As MongoDB is a highly available system, MongoDB can automatically elect one of the secondary nodes as the new primary node.
The election of a new primary node happens when;
- the current primary node becomes unavailable
- a new replica set is initialized and needs to choose its initial primary node
- or when a database administrator initiates a manual failover for maintenance or upgrades.
MongoDB’s voting system ensures only one member becomes a primary, so to speak, there is no split brain.
- Database replica members who are eligible and have the most recent data and minimal replication lag are eligible to become the primary node.
- The choice of which node becomes the primary node is based on which node member receives the most votes.
| Term | Definition |
|---|---|
| Aggregation pipeline | The aggregation pipeline in MongoDB allows for data transformation and processing using a series of stages, including filtering, grouping, sorting, and projecting. The aggregation pipeline is a powerful tool for expressive data manipulation. |
| B+ Tree | The B+ Tree is a data structure commonly used in database indexing to efficiently store and retrieve data based on ordered keys. |
| CRUD | CRUD is an acronym for create, read, update, and delete, which are the basic operations for the basic operations for interacting with and manipulating data in a database. |
| Election | In a MongoDB replica set, an election is the process of selecting a new primary node when the current primary becomes unavailable. |
| Horizontal scaling | The process of adding more machines or nodes to a NoSQL database to improve its performance and capacity. This is typically achieved through techniques like sharding. |
| Idempotent changes | Idempotent operations are those that can be safely repeated multiple times without changing the result. MongoDB encourages idempotent operations to ensure data consistency. |
| Indexing | The creation of data structures that improve query performance by allowing the database to quickly locate specific records based on certain fields or columns. |
| Mongo shell | The MongoDB shell, known as mongo shell, is an interactive command-line interface that allows users to interact with a MongoDB server using JavaScript-like commands. The mongo shell is a versatile tool for administration and data manipulation. |
| MongoClient | MongoClient is the official MongoDB driver that provides a connection to a MongoDB server and allows developers to interact with the database in various programming languages. |
| Oplog | The Oplog is a special collection that records all write operations in a primary node. It is used to replicate data to secondary nodes and recover from failures. |
| Primary node | In a MongoDB replica set, the primary node is the active, writable node that processes all write operations. |
| Replication | Replication involves creating and maintaining copies of data on multiple nodes to ensure data availability, reduce data loss, fault tolerance (improve system resilience), and provide read scalability. |
| Replication lag | Replication lag refers to the delay in data replication from a primary node to its secondary nodes in a replica set. Replication lag can impact the consistency of secondary data. |
| Secondary | Secondary nodes replicate data from the primary and can be used for read-operations. |
| Sharding | Refers to the practice of partitioning a database into smaller, more manageable pieces called shards to distribute data across multiple servers. Sharding helps with horizontal scaling. |
| Vertical scaling | Vertical scaling involves upgrading the resources (For example, CPU and RAM) of existing machines to improve performance. |
Summary
MongoDB is an open source document-oriented database designed to store large data sets for industries. It supports various programming languages such as C, C++, C#, .Net, Go, Java, Node.js, Perl, PHP, Python, Motor, Ruby, Scala, Swift, and Mongoid.
To use the full potential of MongoDB, one should follow several best practices, such as:
- Data Modelling
- Indexing
- Aggregation framework
- Scaling horizontally
- Preventing unauthorized access
| Term | Definition |
|---|---|
| Aggregation pipeline | The aggregation pipeline in MongoDB allows for data transformation and processing using a series of stages, including filtering, grouping, sorting, and projecting. The aggregation pipeline is a powerful tool for expressive data manipulation. |
| Code-first | Code-first refers to a development approach where developers create the application code first and let the code define the database schema. In MongoDB, this means that the schema is flexible and adapts to evolving application needs. |
| Collection | In MongoDB, a collection is a group of MongoDB documents. Collections are analogous to tables in a relational database and store related data documents in a schema-free, JSON-like format. |
| Database | A database in MongoDB is a logical container for one or more collections. It provides an isolation mechanism for collections and their associated data. |
| Document | A NoSQL database model that stores data in semi-structured documents, often in formats like JSON or BSON. These documents can vary in structure and are typically grouped within collections. |
| Extract, transform, and load (ETL) | A process of extracting data from its sources, transforming the data into a business-usable format, and then loading the data into a target database, often used with MongoDB for data integration. |
| Expressive querying | Expressive querying refers to the ability to write complex and flexible queries that address data retrieval and manipulation needs, often facilitated by MongoDB’s query language and aggregation framework. |
| High availability (HA) |
High availability (HA) in MongoDB refers to the ability of the database system to maintain near-continuous operation and data accessibility, even in the face of hardware failures or other issues. High availability is often achieved through features like replication and failover. |
| JSON | JSON is an acronym for JavaScript Object Notation, a lightweight data-interchange format used in NoSQL databases and other data systems. JSON is human-readable and easy for machines to parse. |
| MQL | MongoDB Query Language is a query language specific to MongoDB used to retrieve and manipulate data in the database. |
| NoSQL | NoSQL stands for “not only SQL.” A type of database that provides storage and retrieval of data that is modeled in ways other than the traditional relational tabular databases. |
| Operational data | Operational data in MongoDB refers to the data that the application actively uses and manipulates, as opposed to historical or archived data. |
| Unstructured data | Unstructured data in MongoDB is data that does not adhere to a fixed schema. MongoDB allows for flexible and unstructured data storage, making MongoDB suitable for semi-structured or rapidly changing data. |
| Term | Definition |
|---|---|
| Aggregation pipeline | The aggregation pipeline in MongoDB allows for data transformation and processing using a series of stages, including filtering, grouping, sorting, and projecting. The aggregation pipeline is a powerful tool for expressive data manipulation. |
| B+ Tree | The B+ Tree is a data structure commonly used in database indexing to efficiently store and retrieve data based on ordered keys. |
| CRUD | CRUD is an acronym for create, read, update, and delete, which are the basic operations for the basic operations for interacting with and manipulating data in a database. |
| Election | In a MongoDB replica set, an election is the process of selecting a new primary node when the current primary becomes unavailable. |
| Horizontal scaling | The process of adding more machines or nodes to a NoSQL database to improve its performance and capacity. This is typically achieved through techniques like sharding. |
| Idempotent changes | Idempotent operations are those that can be safely repeated multiple times without changing the result. MongoDB encourages idempotent operations to ensure data consistency. |
| Indexing | The creation of data structures that improve query performance by allowing the database to quickly locate specific records based on certain fields or columns. |
| Mongo shell | The MongoDB shell, known as mongo shell, is an interactive command-line interface that allows users to interact with a MongoDB server using JavaScript-like commands. The mongo shell is a versatile tool for administration and data manipulation. |
| MongoClient | MongoClient is the official MongoDB driver that provides a connection to a MongoDB server and allows developers to interact with the database in various programming languages. |
| Oplog | The Oplog is a special collection that records all write operations in a primary node. It is used to replicate data to secondary nodes and recover from failures. |
| Primary node | In a MongoDB replica set, the primary node is the active, writable node that processes all write operations. |
| Replication | Replication involves creating and maintaining copies of data on multiple nodes to ensure data availability, reduce data loss, fault tolerance (improve system resilience), and provide read scalability. |
| Replication lag | Replication lag refers to the delay in data replication from a primary node to its secondary nodes in a replica set. Replication lag can impact the consistency of secondary data. |
| Secondary | Secondary nodes replicate data from the primary and can be used for read-operations. |
| Sharding | Refers to the practice of partitioning a database into smaller, more manageable pieces called shards to distribute data across multiple servers. Sharding helps with horizontal scaling. |
| Vertical scaling | Vertical scaling involves upgrading the resources (For example, CPU and RAM) of existing machines to improve performance. |