HDFS stands for Hadoop Distributed File System. A distributed file system is a file system that is distributed on multiple file servers and allows programmers to access or store files from any network or computer.
HDFS is the storage layer of Hadoop.
HDFS works by splitting the files into blocks, then creating replicas of the blocks, and storing them on different machines.
HDFS is built to access streaming data seamlessly. Streaming means that HDFS provides a constant bitrate when transferring data rather than having the data being transferred in waves.
HDFS uses a command line interface to interact with Hadoop.
Features
The key features of HDFS are:
The commodity hardware that stores the data is not expensive, and therefore reduces storage costs.
HDFS can store very large amounts of data, as large as petabytes— in any format, tabular and non-tabular.
It splits these large amounts of data into small chunks called blocks.
One of the great features of HDFS is its ability to replicate and minimize the costs associated with data losses when there is failure with one of the hardware units.
That capability makes HDFS fault tolerant. In the event of a data loss of one of the computers, the data can be found on another computer and work continues.
HDFS is also highly scalable. A single cluster can scale into hundreds of nodes.
Portability is also one of the key features, as HDFS is designed to easily move from one platform to another.
Concepts
To get familiar with Hadoop, there are a few concepts to know.
Blocks
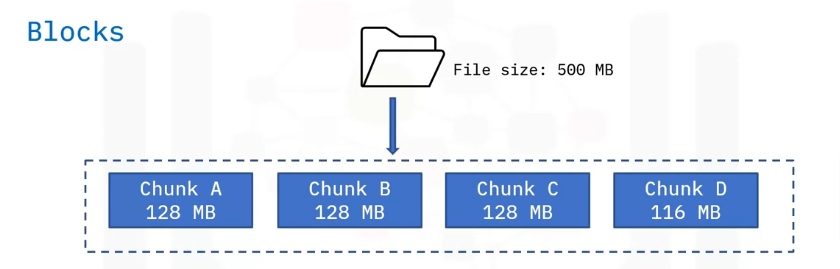
When HDFS receives files, files are broken into smaller chunks called blocks. A block is the minimum amount of data that can be read or written and provides fault tolerance.
Depending on your system configuration, the default block size could be 64 or 128 megabytes.
For example, if we had a 500-megabyte file, with a default block chunk size of 128 megabytes, the file will be divided into 3 blocks of 128 megabytes and one block of 116 megabytes. The only time you will have equal splits is if the file size is a multiple of the default block size.
Therefore, you can see that each file stored doesn’t have to take up the storage of the pre-configured block size.
Nodes
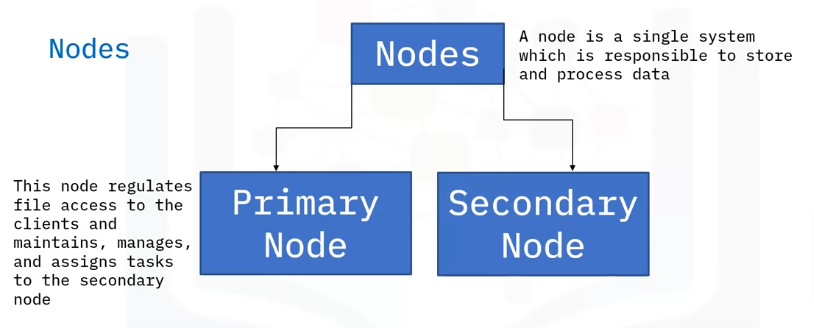
A node is a single system which is responsible for storing and processing data. Think about it as one machine or computer in which data is stored.
Remember that HDFS follows the primary/secondary concept. HDFS has two types of nodes:
Primary Node
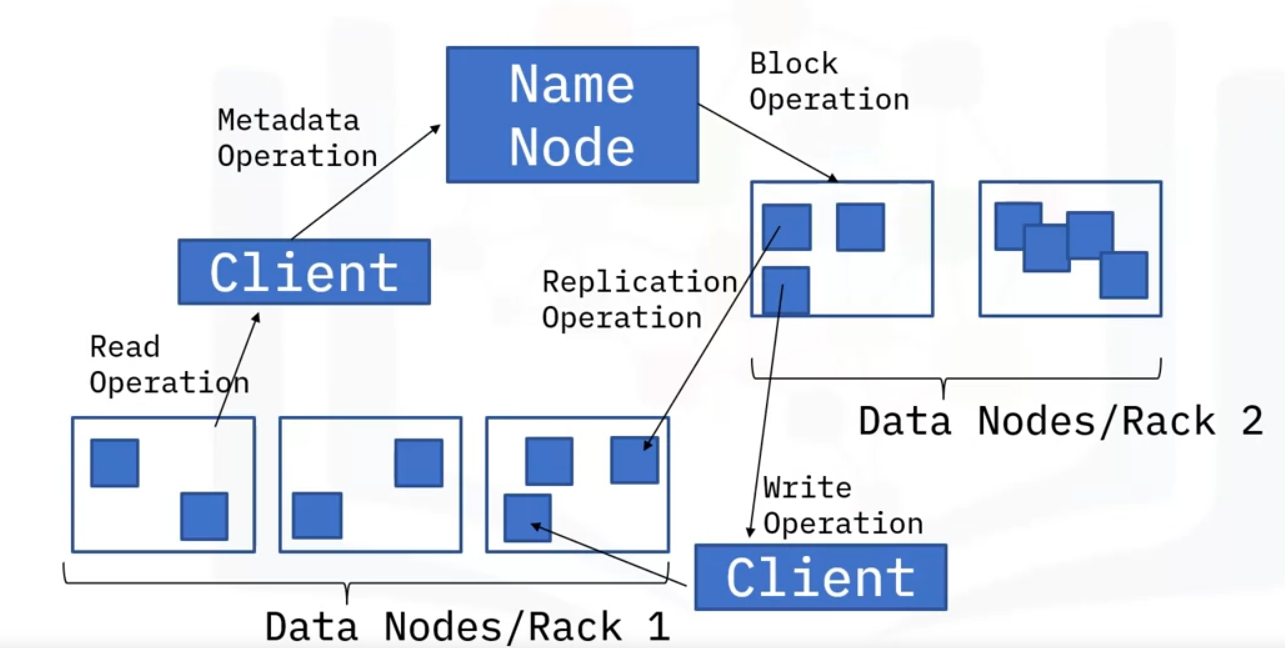
The Primary node, known as the name node, regulates file access to the clients and maintains, manages, and assigns tasks to the secondary node, also known as a data node.
There can be hundreds of data nodes in the HDFS that manage the storage system.
They perform read and write requests at the instruction of the name node.
When performing operations like read and write, it is important that the name node maximizes performance by choosing the data nodes closest to themselves.
This could be by choosing data nodes on the same rack or in nearby racks. This is called rack awareness.
Rack Awareness
Rack awareness is the process of choosing data nodes on the same rack or in nearby racks
A rack is the collection of about forty to fifty data nodes using the same network switch.
Rack awareness is used to reduce the network traffic and improve cluster performance.
To achieve rack awareness, the name node keeps the rack ID information.
Replication is done by rack awareness as well. It is done by making sure replicas of a data node are in different racks. So, if a rack is down, you can still obtain the data from another rack.
Replication
HDFS is known for optimizing replication. HDFS uses the rack awareness concept to create replicas to make sure that the data is reliable and available, and that the network bandwidth is properly utilized.
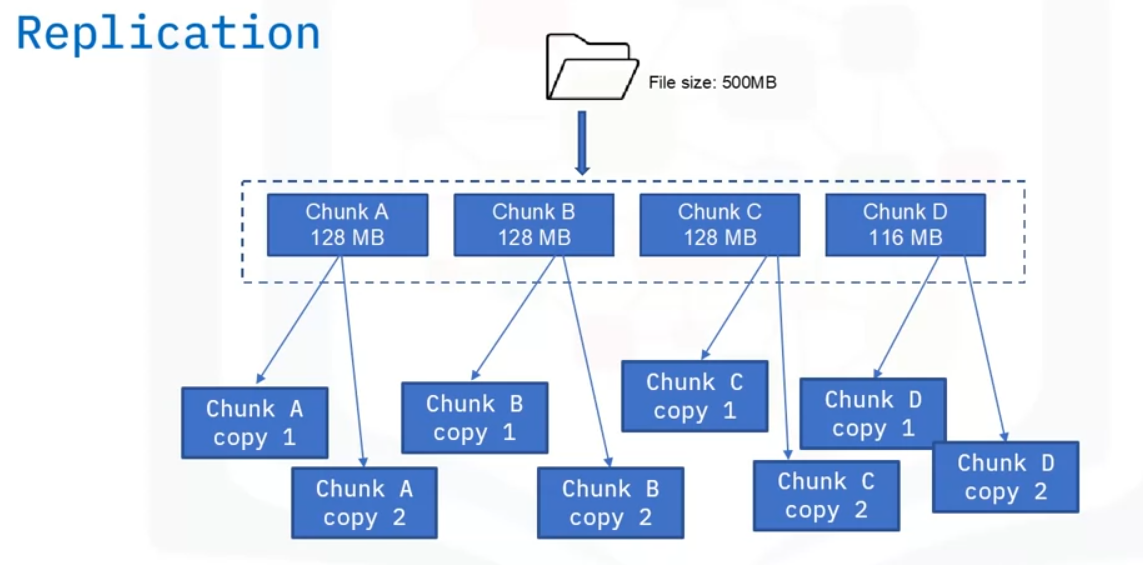
Replication is creating a copy of the data block.
When crashes happen, replication provides backup of the data blocks.
Replication factor is defined as the number of times you make a copy of the data block.
Depending on your configuration, you can set the number of copies you want. Let us look at our 500-megabyte file example. Similar to blocks:
If our replication factor is 2, it will create two copies of each block.
That means we will have 4 times 2, which is eight copies of the file blocks for backup.
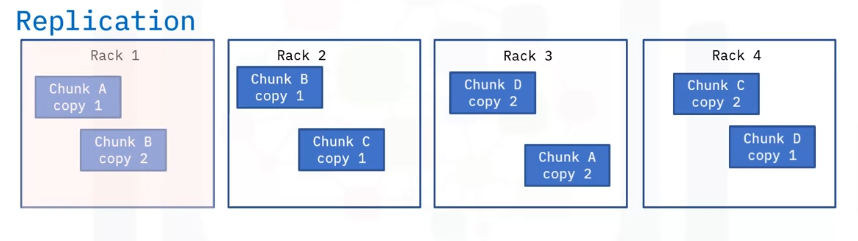
HDFS uses the rack awareness concept and saves the blocks in different racks to make sure that a copy is available in another rack.
For example, you could have four racks of two copies each.
If one of the racks is down or crashes, you will still have a copy of the data blocks in a different rack, and you can still work with the data.
Another important concept is how read and write operations are performed in HDFS.
Read & Write
HDFS allows “write once, read many” operations. This means that you cannot edit files that are already stored in HDFS, but you can append new data to them.
Read
Let us start with how the read operation works.
Assuming we have a text file, the client will send a request to the primary node, which is the name node, to get the location of the data nodes containing blocks.
The name node will verify that the client has the correct privileges and provide the client with the locations. (A client in HDFS interacts with the primary and secondary nodes to fulfill a user’s request.)
The client will then send a request to the closest data nodes through an FS Data Input stream object by calling the read method to read all the files.
When the client is done, the client will use the close method to end the session.
Write
Just like in the read operation, the name node confirms that the client has the write privileges.
The name node makes sure to check that the file doesn’t exist in the system.
If the file already exists, the client will receive an IO exception.
If the file doesn’t exist, the client receives a write permission together with the data nodes.
Once the client is done, the data nodes start creating replicas and sends a confirmation to the client.
Hadoop follows the concept of a primary/secondary node architecture.
The primary node is the name node. The architecture is such that per cluster, there is one name node and multiple data nodes, which are the secondary nodes.
Internally, a file is split into one or more blocks and these blocks are stored in a set of data nodes.
The name node oversees opening, closing, renaming file operations, and mapping file blocks tothe data node.
The data nodes are responsible for read and write requests from the client and perform the creation, replication, and deletion of file blocks based on instructions from the name node.
How To Create Hadoop Cluster
What is a Hadoop Cluster?
A Hadoop cluster is a collection of computers, known as nodes, that are networked together to perform parallel computations on big data sets. The Name node is the master node of the Hadoop Distributed File System (HDFS). It maintains the meta data of the files in the RAM for quick access. An actual Hadoop Cluster setup involves extensives resources which are not within the scope of this lab. In this lab, you will use dockerized hadoop to create a Hadoop Cluster which will have:
A Hadoop environment is configured by editing a set of configuration files:
hadoop-env.sh Serves as a master file to configure YARN, HDFS, MapReduce, and Hadoop-related project settings.
core-site.xml Defines HDFS and Hadoop core properties
hdfs-site.xml Governs the location for storing node metadata, fsimage file and log file.
mapred-site-xml Lists the parameters for MapReduce configuration.
yarn-site.xml Defines settings relevant to YARN. It contains configurations for the Node Manager, Resource Manager, Containers, and Application Master.
For the docker image, these xml files have been configured already. You can see these in the directory /opt/hadoop-3.2.1/etc/hadoop/ by running
ls /opt/hadoop-3.2.1/etc/hadoop/*.xml
/home/project$ git clone https://github.com/ibm-developer-skills-network/ooxwv-docker_hadoop.git# Change directory/home/project$ cd ooxwv-docker_hadoop# Clone applicationtheia@theiadocker-emhrcf:/home/project/ogit clone https://github.com/ibm-develope# Run namenode as a mounted drive on bash/home/project/ooxwv-docker_hadoop$ docker exec-it namenode /bin/bashroot@200d9ff88c53:/# # List files in the directoryroot@200d9ff88c53:/# ls /opt/hadoop-3.2.1/etc/hadoop/*.xml/opt/hadoop-3.2.1/etc/hadoop/capacity-scheduler.xml/opt/hadoop-3.2.1/etc/hadoop/core-site.xml/opt/hadoop-3.2.1/etc/hadoop/hadoop-policy.xml/opt/hadoop-3.2.1/etc/hadoop/hdfs-site.xml/opt/hadoop-3.2.1/etc/hadoop/httpfs-site.xml/opt/hadoop-3.2.1/etc/hadoop/kms-acls.xml/opt/hadoop-3.2.1/etc/hadoop/kms-site.xml/opt/hadoop-3.2.1/etc/hadoop/mapred-site.xml/opt/hadoop-3.2.1/etc/hadoop/yarn-site.xml
In the HDFS, create a directory structure named user/root/input
hdfs dfs -mkdir -p /user/root/input
Copy Config files
Copy all the configuration files over into the input directory
Check if file has been copied by viewing the data.txt file
hdfs dfs -cat /user/root/data.txt
Which displays a long text file in the terminal
# Create a fileroot@200d9ff88c53:/# hdfs dfs -mkdir -p /user/root/input# Copy all config files to input directoryroot@200d9ff88c53:/# hdfs dfs -put $HADOOP_HOME/etc/hadoop/*.xml /user/root/input# Create data.txt fileroot@200d9ff88c53:/# curl https://raw.githubusercontent.com/ibm-developer-skills-network/ooxwv-docker_hadoop/master/SampleMapReduce.txt --output data.txt% Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed1006858100685800566190--:--:----:--:----:--:--56677# Copy data.txt file into /user/rootroot@200d9ff88c53:/# hdfs dfs -put data.txt /user/root/2024-10-2822:06:08,120 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false# Check if file has been copiedroot@200d9ff88c53:/# hdfs dfs -cat /user/root/data.txt
View HDFS GUI
Click on View HDFS icon
Input port: 9870
Click your application to open GUI
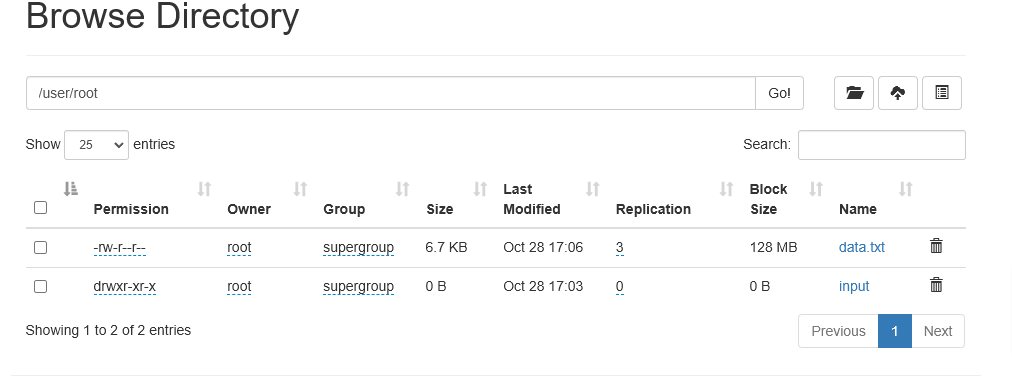
In the file directory table > choose user > root
Notice that the block size is 128 MB though the file size is actually much smaller. This is because the default block size used by HDFS is 128 MB.
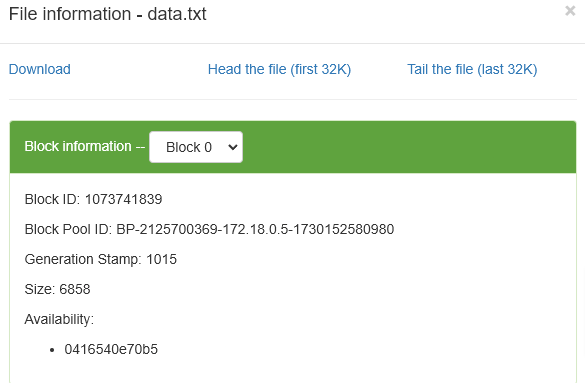
You can click on the file to check the file info.
It gives you information about the file in terms of number of bytes, block id etc.,