Design Patterns
MongoDB design patterns help
- Optimize data models based on application queries and usage
- Improve application performance by reducing schema complexity
- Help identify data storage patterns and the type of data returned to the application
- Are best practices for Structuring data and queries to optimize performance, scalability, and maintainability
- Some prominent MongoDB design patterns include
- approximation
- attribute
- polymorphic
- outliers
- bucket
Approximation
Helps calculate frequent expenses, where the precision for those calculations is not a priority.
For example, Instagram followers are for celebrities. The approximation design pattern is useful for fewer WRITES to the database and maintains statistically valid numbers. However, it cannot represent exact numbers.
Attribute
Helps document various characteristics and similar fields that you cannot identify when raising a query. This attribute is useful when the fields need to be sorted and found in a small subset of documents or when both conditions meet within the documents, such as when selling products on e-commerce.
The attribute MongoDB design pattern is useful in less indexing and generating simple and faster queries.
Polymorphic
Helps store different documents in the same collection. However, it often uses a discriminator field to differentiate between types of documents, such as customer communication stored using various channels.
This type of design pattern is easy to implement and runs queries across a single collection.
Outlier
Useful for queries or documents that don’t fit into the typical data pattern, such as a list of a celebrity’s social media followers (which could be in millions).
This design pattern prevents documents or queries from determining an application’s solution; however, it is tailored for typical use cases but doesn’t address ad hoc queries.
Bucket Pattern
Helps to manage streaming data such as time series, real-time analytics, or Internet of Things (IoT) applications. The bucket MongoDB design pattern reduces the number of documentation while collecting them, improves index performance, and simplifies data access by leveraging pre-aggregation.
For example: Collecting weather data using multiple sensors. This data collection helps to reduce efforts to review temperature and wind speed every minute. However, you would receive a summary per hour, such as:
- Average temperature
- Average wind speed
However, you can review the weather forecast in detail. For example, find the temperature per minute and calculate the median and variance. The benefit of the bucket design pattern is that it doesn’t repeat device identifiers and entry data with every record. However, if this didn’t happen, there would be 1440 records per device per hour, creating a large amount of data.
CAP Theorem
In the early 2000s big data Hadoop architecture was being created as the first open source, distributed architecture that can store and process high volumes of data. At this time, more and more services were developed that required databases to be distributed as well.
Actually, these businesses required not only that their services were active and accessible in most parts of the world, but also that their services were always available.
For relational databases that rely so much on the consistency of data, the new concept of availability while having a distributed system seemed impossible, and this was proven by the CAP Theorem. You can use the CAP Theorem to classify NoSQL databases.
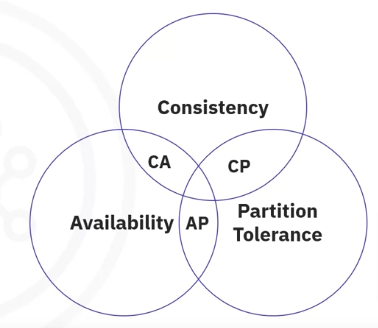
The theorem states that there are three essential system requirements necessary for the successful design, implementation, and deployment of applications in distributed systems: Consistency, Availability, and Partition Tolerance, or CAP. A distributed system can guarantee delivery of only two of these three desired characteristics.
Consistency refers to whether a system operates fully or not. Do all nodes within a cluster see all the data they are supposed to?
Availability means just as it sounds. Does each request get a response outside of failure or success?
Partition Tolerance represents the fact that a given system continues to operate even under circumstances of data loss or network failure.
While consistency and availability seem straightforward, let’s see what partition tolerance refers to.
A partition is a communications break within a distributed system—a lost or temporarily delayed connection between nodes. Partition tolerance means that the cluster must continue to work despite any number of communication breakdowns between nodes in the system. In distributed systems, partitions can’t be avoided. Therefore, partition tolerance becomes a basic feature of native distributed systems such as NoSQL.
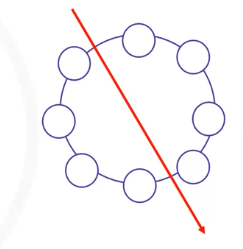
Example:
In a cluster with eight distributed nodes, a network partition could occur, and communication will be broken between all the nodes.
- In our case, instead of one 8-node cluster we will have two smaller 4-node clusters available.
- Consistency between the two clusters will be achieved when network communication is re-established.
- Partition tolerance has become more of a necessity than an option in distributed systems. It is made possible by sufficiently replicating records across combinations of nodes and networks.
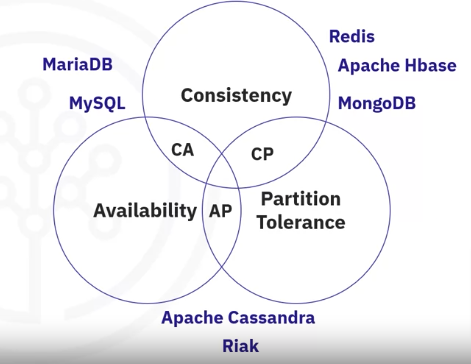
For such systems as NoSQL, since partition tolerance is mandatory, a system can be either Consistent and Partition Tolerant (CP) or Available and Partition Tolerant (AP). Existing NoSQL systems, like MongoDB or Cassandra, can be classified using CAP Theorem.
- MongoDB chooses consistency as the primary design driver of the solution
- Apache Cassandra chooses availability.
- This doesn’t mean that MongoDB cannot be available, or that Cassandra cannot become fully consistent. It means that these solutions first ensure that they are consistent (in the case of MongoDB) or available (in the case of Cassandra) and the rest is tunable