emp_id,emp_name,salary
198,Donald,2600
199,Douglas,2600
200,Jennifer,4400
201,Michael,13000
202,Pat,6000
203,Susan,6500Setup Hive and Bee
HIVE
Hive is a data warehouse software within Hadoop that is designed to read, write, and manage large, tabular-type datasets and data analysis.
A data warehouse stores historical data from many different sources so that you can analyze and extract insights from it. These insights are used for reporting.
- Hive is scalable and fast because it is designed to work on petabytes of data.
- It is easy to use if you are familiar with SQL because Hive query language, or Hive QL, is based on SQL.
- Hive supports the following file formats:
- Sequence files consisting of binary key value pairs
- Record columnar files that store columns of a table in a columnar database
- Text or flat files.
- Hive allows for data cleaning and filtering tasks according to users’ requirements.
RDBMS vs HIVE
RDBMS is a type of database management system specifically designed for relational databases.
- RDBMS is the acronym for Relational Database Management System.
- A relational database is a database that stores data in a structured format using rows and columns known as a table.
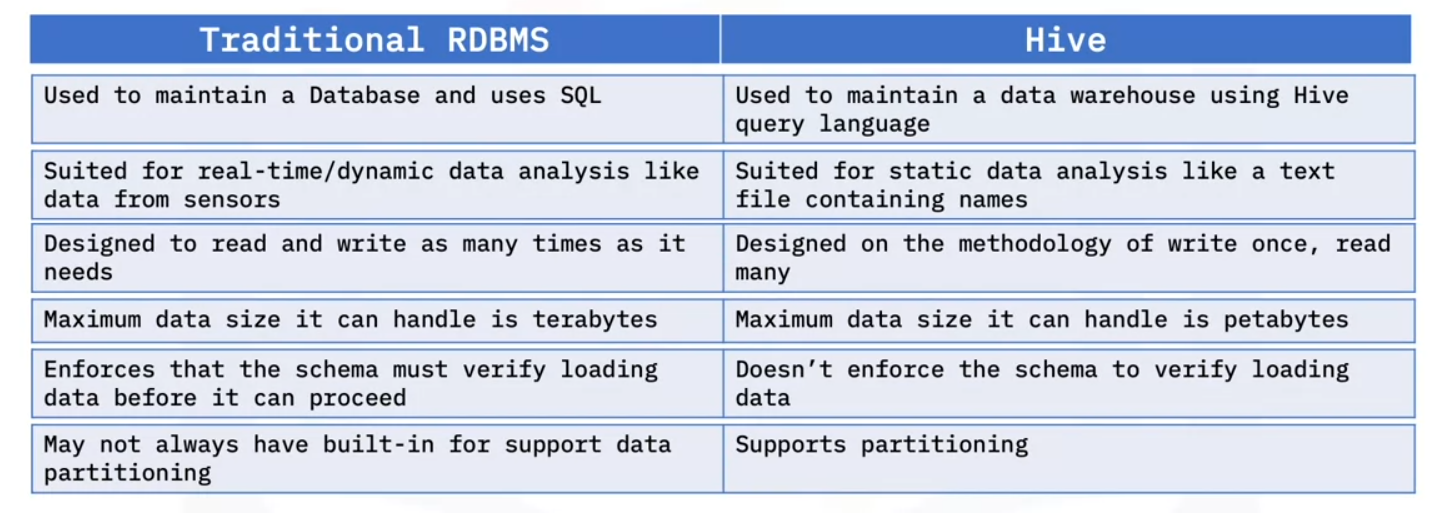
Let’s look at the differences between a traditional RDBMS and Hive.
- Traditional RDBMS is used to maintain a database and uses the structured query language known as SQL.
- Hive is used to maintain a data warehouse and uses the Hive query language, a language inspired by SQL.
- Traditional RDBMS is suited for real-time data analysis, like data from sensors.
- Hive is suited for static data analysis.
- Traditional RDBMS allows for as many read and write operations a user needs.
- Hive is based on the write once, read many methodology.
- Traditional RDBMS can handle up to terabytes of data.
- Hive is designed to handle as much as petabytes of data.
- RDBMS enforces that the schema must verify loading data before it can proceed.
- Hive doesn’t enforce the schema to verify loading data.
- Lastly, traditional RDBMS may not always have built-in for support data partitioning.
- Hive supports partitioning. Partitioning means dividing the table into parts based on the values of a particular column such as date or city.
Architecture
This is what the Hive architecture looks like.
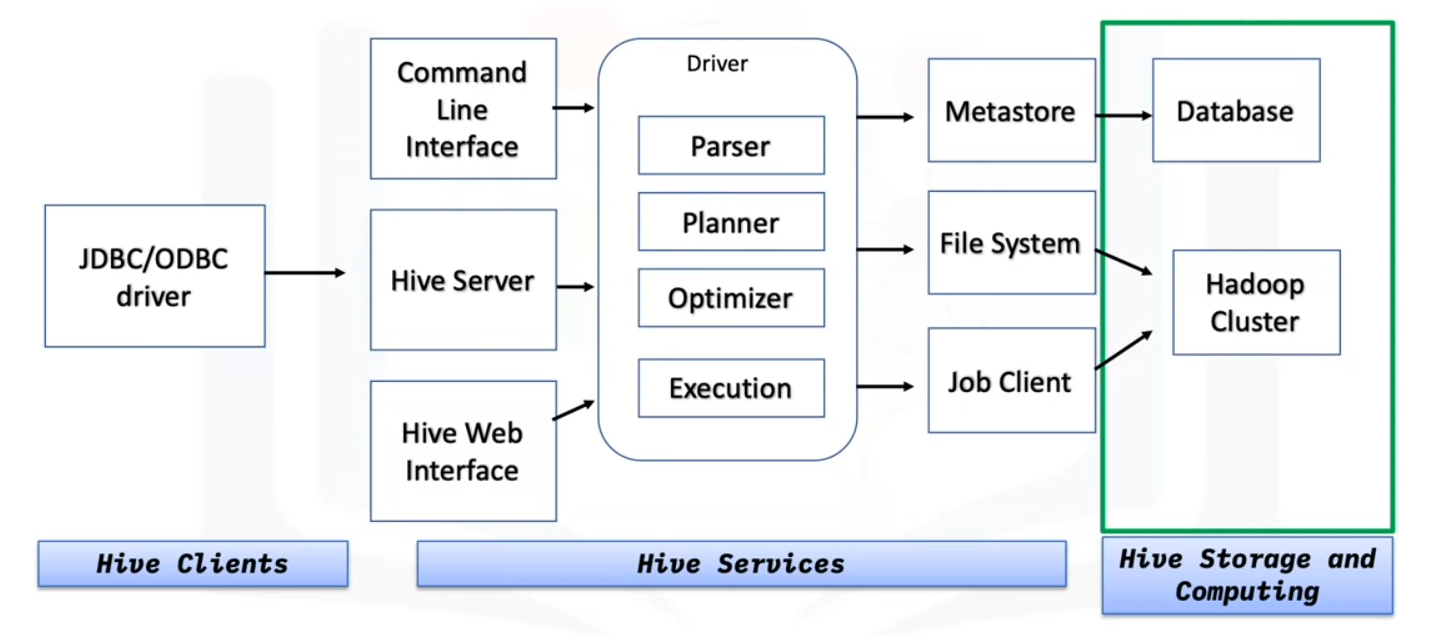
There are three main parts of the architecture:
- The Hive clients: Hive provides different drivers for communication depending on the type of application.
- For example, for Java based applications, it uses JDBC drivers, and other types of applications will use ODBC drivers. These drivers communicate with the servers.
- Hive services:
- Client interactions are done through the Hive services. Any query operations are done here.
- The command line interface acts as an interface for the Hive service.
- The driver takes in query statements, monitors the progress and life cycle of each session, and stores metadata generated from the query statements.
- The meta store stores the metadata, the data and information about each table, such as the location and schema.
- The meta store, file system, and job client in turn communicate with
- Hive storage and computing to perform the following: - Metadata information of tables are stored in some sort of database and query results and data loaded in the tables are stored in Hadoop cluster or HDFS.
Let’s look at the concepts in detail.
Hive Client

Components in the Hive clients include:
- The JDBC client, which allows Java-based applications to connect to Hive, and
- the ODBC client, which allows applications based on the ODBC protocol to connect to Hive.
Hive Services
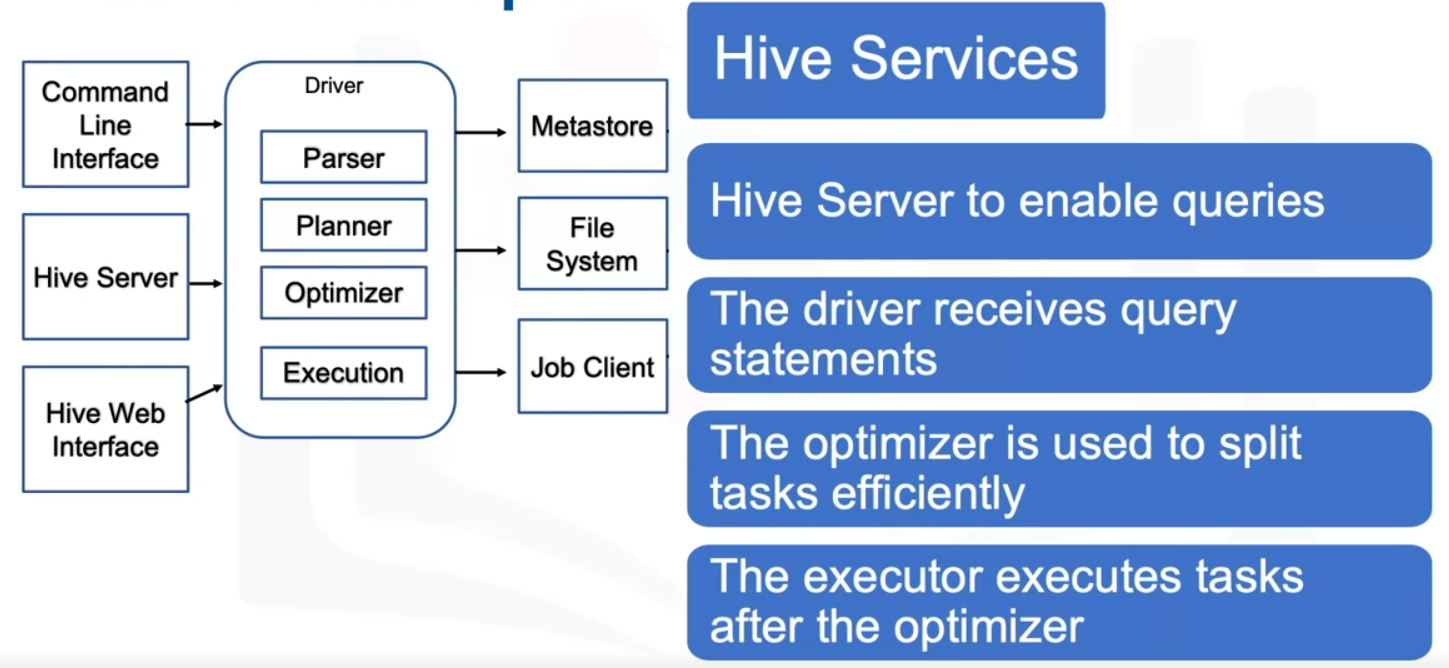
The Hive services section of the architecture is in charge of performing queries.
- The Hive server is used to run queries and allows multiple clients to submit requests.
- It is built to support the JDBC and ODBC clients.
- The driver receives query statements submitted through the command line and sends the query to the compiler after initiating a session.
- The optimizer performs transformations on the execution plan and splits the tasks to help speed up and improve efficiency.
- The executor executes tasks after the optimizer has split the tasks.
Hive Storage & Computing
- The meta store is storage for the metadata, which is information about the table.
- The meta store is in charge of keeping this information in a central place.
How To Use Hive
I will be demonstrating the use of Hive on the cloud. Import data in csv format. Create Table. Load data into the table, and finally query the table
CLI Terminal
- Open an instance of your cloud server
- Open a new terminal
Create Directory
- create data directory in the project directory:
mkdir /home/project/data
Change Diretories
cd /home/project/data
Download Data
wget https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBM-BD0225EN-SkillsNetwork/data/emp.csv
View Data
- Open the file and view the sample data
- We’ll use the Hive from the docker hub for this example.
- Pull the Hive image into your system by running:
docker pull apache/hive:4.0.0-alpha-1
Run Hive Server
- Run the hive server on port 10002.
- Name the server instance myhiveserver.
- Mount the local data folder in the hive server as hive_custom_data.
- This would mean that the whole data folder that you created locally, along with anything you add in the data folder, is copied into the container under the directory hive_custom_data
- Use:
docker run -d -p 10000:10000 -p 10002:10002 --env SERVICE_NAME=hiveserver2 -v /home/project/data:/hive_custom_data --name myhiveserver apache/hive:4.0.0-alpha-1
Open Hive Server GUI
- Open HiveServer GUIand look at the Hive server
- Under Other > Click on Launch Application
- Input the port number: 10002
Access beeline
- Access beeline
- This is where you can create, modify, delete table and access the data in the table
docker exec -it myhiveserver beeline -u 'jdbc:hive2://localhost:10000/'
Create Table
- Create a new table Employee with three columns as in the csv file: em_id, emp_name, salary_
create table Employee(emp_id string, emp_name string, salary int) row format delimited fields terminated by ',' ;
Check Table
- Check if the table is created
show tables;- This will list the Employee table
Load Data from CSV
LOAD DATA INPATH '/hive_custom_data/emp.csv' INTO TABLE Employee;
List all Rows
SELECT * FROM employee;
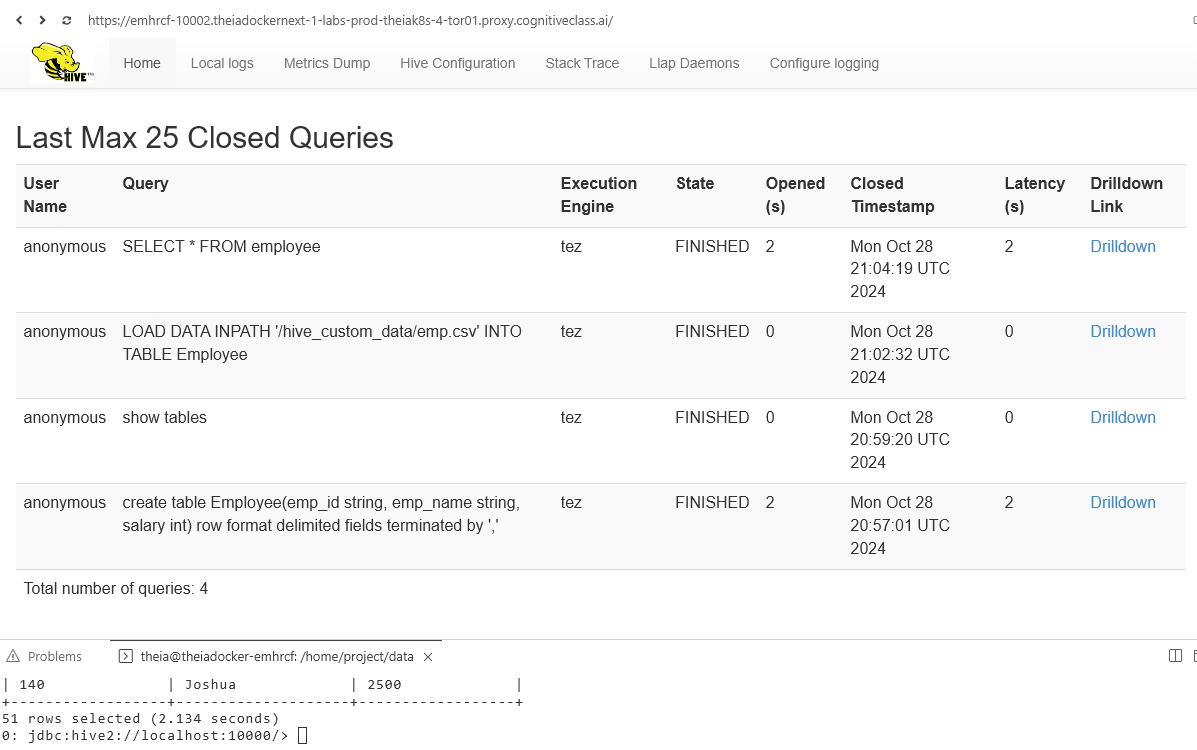
View Details in GUI
- In the Home Tab
- You can see the list of queries we just performed
Hive internally uses MapReduce to process and analyze data. When you execute a Hive query, it generates MapReduce jobs that run on the Hadoop cluster.
Quit beehive
CTRL + D
/home/project$ mkdir /home/project/data
/home/project$ cd /home/project/data
# Download Data
/home/project/data$ wget https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBM-BD0225EN-SkillsNetwork/data/emp.csv
# Pull Hive image
/home/project/data$ docker pull apache/hive:4.0.0-alpha-1
4.0.0-alpha-1: Pulling from apache/hive
1efc276f4ff9: Pull complete
a2f2f93da482: Pull complete
1a2de4cc9431: Pull complete
d2421c7a4bbf: Pull complete
94537d112428: Pull complete
c1c180ff1f7a: Pull complete
e7bf3bcb5626: Pull complete
03dc5be35f32: Pull complete
f40d13a78683: Pull complete
bbc9e14bf9a1: Pull complete
1a47e3a1960a: Pull complete
1111ce1bbac2: Pull complete
4f4fb700ef54: Pull complete
Digest: sha256:b06cfa5eb6e70a9ad6fbdbaef8369b7f4832b1adb892adce118d3eec474dc7ae
Status: Downloaded newer image for apache/hive:4.0.0-alpha-1
docker.io/apache/hive:4.0.0-alpha-1
# Setup Hive
/home/project/data$ docker run -d -p 10000:10000 -p 10002:10002 --env SERVICE_NAME=hiveserver2 -v /home/project/data:/hive_custom_data --name myhiveserver apache/hive:4.0.0-alpha-1
ef254b8992a25e5f71cca5ec7172a3de57de06b889a9d8ca8f08151f696fef02
# Open HiveServre CLI using the icon
#
/home/project/data$ docker exec -it myhiveserver beeline -u 'jdbc:hive2://localhost:10000/'
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hive/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hive/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Connecting to jdbc:hive2://localhost:10000/
Connected to: Apache Hive (version 4.0.0-alpha-1)
Driver: Hive JDBC (version 4.0.0-alpha-1)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 4.0.0-alpha-1 by Apache Hive
0: jdbc:hive2://localhost:10000/>
# Create Table
0: jdbc:hive2://localhost:10000/> create table Employee(emp_id string, emp_name string, salary int) row format delimited fields terminated by ',' ;
INFO : Compiling command(queryId=hive_20241028205658_dcca05c6-9159-4d27-9057-18cc32dcb406): create table Employee(emp_id string, emp_name string, salary int) row format delimited fields terminated by ','
INFO : Semantic Analysis Completed (retrial = false)
INFO : Created Hive schema: Schema(fieldSchemas:null, properties:null)
INFO : Completed compiling command(queryId=hive_20241028205658_dcca05c6-9159-4d27-9057-18cc32dcb406); Time taken: 1.799 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=hive_20241028205658_dcca05c6-9159-4d27-9057-18cc32dcb406): create table Employee(emp_id string, emp_name string, salary int) row format delimited fields terminated by ','
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=hive_20241028205658_dcca05c6-9159-4d27-9057-18cc32dcb406); Time taken: 0.743 seconds
No rows affected (2.79 seconds)
# Check if Table is created
0: jdbc:hive2://localhost:10000/> show tables;
INFO : Compiling command(queryId=hive_20241028205920_f59a2fb5-046c-48cc-bfd4-5eb833b02073): show tables
INFO : Semantic Analysis Completed (retrial = false)
INFO : Created Hive schema: Schema(fieldSchemas:[FieldSchema(name:tab_name, type:string, comment:from deserializer)], properties:null)
INFO : Completed compiling command(queryId=hive_20241028205920_f59a2fb5-046c-48cc-bfd4-5eb833b02073); Time taken: 0.081 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=hive_20241028205920_f59a2fb5-046c-48cc-bfd4-5eb833b02073): show tables
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=hive_20241028205920_f59a2fb5-046c-48cc-bfd4-5eb833b02073); Time taken: 0.119 seconds
+-----------+
| tab_name |
+-----------+
| employee |
+-----------+
1 row selected (0.396 seconds)
# Load Data from csv
0: jdbc:hive2://localhost:10000/> LOAD DATA INPATH '/hive_custom_data/emp.csv' INTO TABLE Employee;
INFO : Compiling command(queryId=hive_20241028210232_559cb98d-76de-4cb9-ac14-e799ea2b6f60): LOAD DATA INPATH '/hive_custom_data/emp.csv' INTO TABLE Employee
INFO : Semantic Analysis Completed (retrial = false)
INFO : Created Hive schema: Schema(fieldSchemas:null, properties:null)
INFO : Completed compiling command(queryId=hive_20241028210232_559cb98d-76de-4cb9-ac14-e799ea2b6f60); Time taken: 0.182 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=hive_20241028210232_559cb98d-76de-4cb9-ac14-e799ea2b6f60): LOAD DATA INPATH '/hive_custom_data/emp.csv' INTO TABLE Employee
INFO : Starting task [Stage-0:MOVE] in serial mode
INFO : Loading data to table default.employee from file:/hive_custom_data/emp.csv
INFO : Starting task [Stage-1:STATS] in serial mode
INFO : Executing stats task
INFO : Table default.employee stats: [numFiles=1, numRows=0, totalSize=854, rawDataSize=0, numFilesErasureCoded=0]
INFO : Completed executing command(queryId=hive_20241028210232_559cb98d-76de-4cb9-ac14-e799ea2b6f60); Time taken: 0.25 seconds
No rows affected (0.457 seconds)
# List all rows from Table
0: jdbc:hive2://localhost:10000/> SELECT * FROM employee;
INFO : Compiling command(queryId=hive_20241028210417_30e53dbd-d31e-4e77-9105-24e98e79c00a): SELECT * FROM employee
INFO : No Stats for default@employee, Columns: emp_name, salary, emp_id
INFO : Semantic Analysis Completed (retrial = false)
INFO : Created Hive schema: Schema(fieldSchemas:[FieldSchema(name:employee.emp_id, type:string, comment:null), FieldSchema(name:employee.emp_name, type:string, comment:null), FieldSchema(name:employee.salary, type:int, comment:null)], properties:null)
INFO : Completed compiling command(queryId=hive_20241028210417_30e53dbd-d31e-4e77-9105-24e98e79c00a); Time taken: 2.097 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=hive_20241028210417_30e53dbd-d31e-4e77-9105-24e98e79c00a): SELECT * FROM employee
INFO : Completed executing command(queryId=hive_20241028210417_30e53dbd-d31e-4e77-9105-24e98e79c00a); Time taken: 0.001 seconds
+------------------+--------------------+------------------+
| employee.emp_id | employee.emp_name | employee.salary |
+------------------+--------------------+------------------+
| emp_id | emp_name | NULL |
| 198 | Donald | 2600 |
| 199 | Douglas | 2600 |
| 137 | Renske | 3600 |
| 138 | Stephen | 3200 |
| 139 | John | 2700 |
| 140 | Joshua | 2500 |
+------------------+--------------------+------------------+
51 rows selected (2.134 seconds)
# Quit CTRL+D
0: jdbc:hive2://localhost:10000/> CTRL+D
[WARN] Failed to create directory: /home/hive/.beeline
No such file or directory
Closing: 0: jdbc:hive2://localhost:10000/
theia@theiadocker-emhrcf:/home/project/data$