# Dowload data to our environment
/home/project$ curl https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz --output hadoop-3.3.6.tar.gz
# Extract tar file
/home/project$ tar -xvf hadoop-3.3.6.tar.gz
# move to directory
/home/project$ cd hadoop-3.3.6
/home/project/hadoop-3.3.6$
# Verify Hadoop setup
/home/project/hadoop-3.3.6$ bin/hadoop
Usage: hadoop [OPTIONS] SUBCOMMAND [SUBCOMMAND OPTIONS]
or hadoop [OPTIONS] CLASSNAME [CLASSNAME OPTIONS]
where CLASSNAME is a user-provided Java class
OPTIONS is none or any of:
--config dir Hadoop config directory
--debug turn on shell script debug mode
--help usage information
buildpaths attempt to add class files from build tree
hostnames list[,of,host,names] hosts to use in worker mode
hosts filename list of hosts to use in worker mode
loglevel level set the log4j level for this command
workers turn on worker mode
SUBCOMMAND is one of:
Admin Commands:
daemonlog get/set the log level for each daemon
Client Commands:
archive create a Hadoop archive
checknative check native Hadoop and compression libraries availability
classpath prints the class path needed to get the Hadoop jar and the required
libraries
conftest validate configuration XML files
credential interact with credential providers
distch distributed metadata changer
distcp copy file or directories recursively
dtutil operations related to delegation tokens
envvars display computed Hadoop environment variables
fs run a generic filesystem user client
gridmix submit a mix of synthetic job, modeling a profiled from production
load
jar <jar> run a jar file. NOTE: please use "yarn jar" to launch YARN
applications, not this command.
jnipath prints the java.library.path
kdiag Diagnose Kerberos Problems
kerbname show auth_to_local principal conversion
key manage keys via the KeyProvider
rumenfolder scale a rumen input trace
rumentrace convert logs into a rumen trace
s3guard S3 Commands
trace view and modify Hadoop tracing settings
version print the version
Daemon Commands:
kms run KMS, the Key Management Server
registrydns run the registry DNS server
SUBCOMMAND may print help when invoked w/o parameters or with -h.
# Download data.txt to local directory
/home/project/hadoop-3.3.6$ curl https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBM-BD0225EN-SkillsNetwork/labs/data/data.txt --output data.txt
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 47 100 47 0 0 339 0 --:--:-- --:--:-- --:--:-- 340
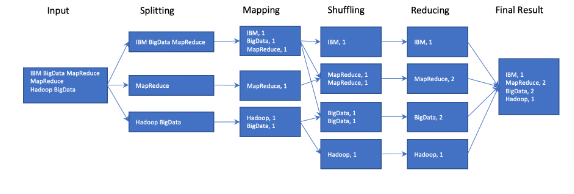
# Run MapReduce on file and store in user/root/output
/home/project/hadoop-3.3.6$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount data.txt output
# See the output file generated
:/home/project/hadoop-3.3.6$ ls output
_SUCCESS part-r-00000
# View the output of word count
:/home/project/hadoop-3.3.6$ cat output/part-r-00000
BigData 2
Hadoop 1
IBM 1
MapReduce 2How To Use - 2
MapReduce
MapReduce is a programming pattern that enables massive scalability across hundreds or thousands of servers in a Hadoop cluster. As the processing component, MapReduce is the heart of Apache Hadoop.
- MapReduce is a processing technique and a program model for distributed computing, it is based on Java, can also be coded in C++, Python, Ruby, R
- Distributed computing is a system or machine with multiple components located on different machines.
- Each component has its own job, but the components communicate with each other to run as one system to the end user.”
- The MapReduce algorithm consists of two important tasks - Map and Reduce.
Map
As the name suggests, the MapReduce framework contains two tasks, Map and Reduce.
Map takes in an input file and performs some mapping tasks by processing and extracting important data information into a key value pairs and these are the preliminary output list.
Some more reorganization goes on before the preliminary output is sent to the Reducer.
Reduce
The Reducer works with multiple map functions and aggregates the pairs using their keys to produce a final output. MapReduce keeps track of its tasks by creating unique keys to ensure that all the processes are solving the same problem.
Input
The input data is a file that is saved in the Hadoop file system called HDFS.
Example
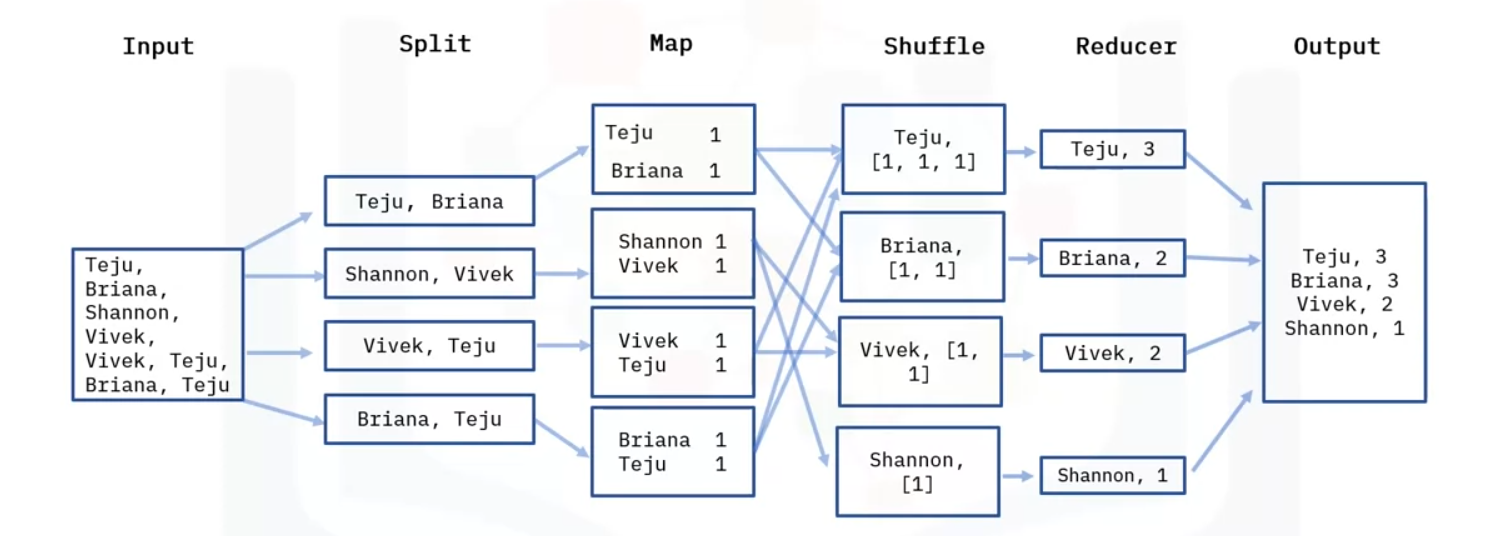
Input
- Now let’s assume we have an input file that contains names of people, and we would like to do a word count on the unique name occurrences.
Map
- First, the data is split into the following four files, each of them in key value pair and are worked on separately.
- For example, for the first split line for Teju and Briana, we have two key value pairs with one occurrence in each file
- It will do the same for all of key value pairs.
Reduce
- We then have the reducer; the reducer processes the data that comes from the map.
- The Reducer starts with shuffling. Shuffling sorts the key and a list of values in a list, for example, you will see the Key Teju and the corresponding list of values from the previous step.
- We will have Teju [1, 1, 1], This is because the name Teju occurred 3 times in the “Map” step.
- It does the same for the rest of the names, counting how many times they appeared in the“Map” step.
- The Reducer layer then aggregates the values in the list and saves them, then the final output is saved in an output file, which will be stored in the HDFS.
Advantages
Parallel Computing
The advantages of MapReduce is its ability to allow for a high level of parallel jobs across multiple nodes. A node is an independent computer used for processing and storing big volumes of data.
Splitting Independent Tasks
In Hadoop we have two types of nodes, the name node and the data node. Map reduce allows for splitting and running independent tasks in parallel by dividing each task which in turn saves time.
Variety of Data Processed
MapReduce is very flexible and can process data that come in tabular and non-tabular forms. Therefore, MapReduce provides business value to organizations regardless of how their data is structured.
Multiple Language Support
It offers support for different languages
Platform for Analysis
It provides a platform for analysis, data warehousing and more.
Use Cases
Some use cases not displayed above:
Video Streaming
Map reduce is used by Netflix to recommend movies based on what you have watched in the past by using the user’s interests.
Financial Institutions
It is also used in financial institutions like banks and credit card companies to flag and detect anomalies in user transactions.
Advertisement
It can also be used in the advertisement industry to understand a user’s behavior by how they engage with ads. Google ads work by using MapReduce to understand the engagement of users with an ad.
How To Use - 1
The steps outlined in this lab use the single-node Hadoop Version 3.3.6 Hadoop is most useful when deployed in a fully distributed mode on a large cluster of networked servers sharing a large volume of data. However, for basic understanding, we will configure Hadoop on a single node.
We will run the WordCount example with an input text and see how the content of the input file is processed
Download Data
Start New Terminal
- Since we are in the cloud, start a new terminal
Download Tar File
curl https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz --output hadoop-3.3.6.tar.gz
Extract tar file
tar -xvf hadoop-3.3.6.tar.gz
Move to Directory
cd hadoop-3.3.6
Verify Hadoop Setup
- Check the hadoop command to see if it is setup. This will display the usage documentation for the hadoop script
bin/hadoop
Download Data to Directory
- Download data.txt to current directory
curl https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBM-BD0225EN-SkillsNetwork/labs/data/data.txt --output data.txt
Run MapReduce
- Run the Mapreduce application for wordcount on data.txt and store the output in /user/root/output
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount data.txt output
List the Output
- Once the word count runs successfully, you can run the following command to see the output file it has generated
ls output- output should be:
_SUCCESSand the name: part-r-00000
View the Output
- It might take a couple minutes to be processed
- To view the word count output run
cat output/part-r-00000
Clean up previous File
- Delete the data file as well as the output folder from above
rm data.txtrm -rf output
Create Text File
- Use text editor to create data.txt
- Use the following
Save file
- Save the above file in Hadoop directory
Run MapReduce
- To run wordcount use and save it in user/root/output
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount data.txt output
Italy Venice
Italy Pizza
Pizza Pasta GelatoList Output
ls output_SUCCESS part-r-00000
View Output
cat output/part-r-00000
rm data.txt
rm -rf output
# Run MapReduce to run wordcount and save in output
:/home/project/hadoop-3.3.6$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount data.txt output
# List Output
/home/project/hadoop-3.3.6$ ls output
_SUCCESS part-r-00000
# View Output
/home/project/hadoop-3.3.6$ cat output/part-r-00000
Gelato 1
Italy 2
Pasta 1
Pizza 2
Venice 1
# Quit
CTRL+D
Social Media
MapReduce can be used for social media platforms like LinkedIn and Instagram to analyze who visited, viewed, and interacted with your profile posts.