training> db.marks.aggregate([
{"$sort":{"marks":-1}},
{"$limit":2}
])
# OUTPUT
[
{
_id: ObjectId('6718163c3d4a8d9dbd96403d'),
name: 'Steve',
subject: 'english',
marks: 89
},
{
_id: ObjectId('6718163c3d4a8d9dbd964033'),
name: 'Ramesh',
subject: 'maths',
marks: 87
}
]Group By
Aggregation
An aggregation framework, which is also sometimes referred to as an aggregation pipeline, is a series of operations that you apply on your data to obtain a sought after outcome.
The MongoDB aggregation framework provides powerful tools for performing data transformations, analytics, and computations within the database. Instead of fetching large datasets and processing them in application code, the aggregation pipeline can be used to perform complex operations directly within MongoDB. However, you should familiarize yourself with aggregation operators and stages, such as $match, $group, $project, and $lookup, to manipulate and aggregate data efficiently.
For example: to understand whether students are really developing their knowledge, you want to see the average student scores in 2020 organized by courseid.
- To obtain this information, you will need to filter the 2020 documents,
- then group those documents by course,
- then calculate the average score.
Processing this code is like running a pipeline. Documents enter from one side, go through one or more processes, and come out in the sought after format at the other end.
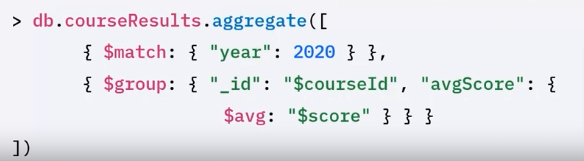
- When you apply the $match stage, MongoDB filters out those documents that do not have the year 2020.
- MongoDB only takes documents that meet all criteria to the next stage.
- Next the $group stage separates documents into groups according to a group key.
- A group key is often a field or group of fields, you’ll use the id field to set the group key.
- The output is one document for each unique group key.
- In this example, the group key is the courseid. The dollar sign means value from the document.
- Average score is a field that will hold the average score. $average returns the average of the numeric values in the field score, represented as $scores.
- The output will display two documents, one document for courseid 1, and one document for courseid 2.
- You’ll also see each course’s average course scores for the year 2020.
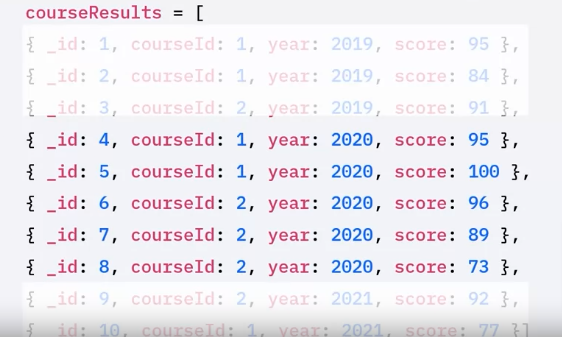
Common Aggregation Stages
An aggregation stage can be repeated in a pipeline, and the most common stages are
- $project stage reshapes documents by including or excluding fields
- $sort stage sorts the documents in requested order by field
- $counts documents in that stage, and
- $merge to move output to a collection.
Project Stage

Let’s use this student’s data to see $project in action.
- You apply $project stage to only take first and lastName when using $project.
- With First and lastName, you only see those fields and id is always included unless explicitly excluded.

Sort Stage

- You can add $sort to always see the results in a specific order.
- You can specify a sort order based on any field in the document at that stage of pipeline.
- For this example, you are sorting by last name in descending order, which is represented by -1
- For ascending order, you use a 1 without a negative mark.
- The output displays student documents with first and last name along withunderscore id with the students in descending order on the last name.

Count Stage

- Use $count to calculate the total number of students andassign the outcome to a field called totalStudents
- Which produces the outcome of totalStudents as 3
Merge Stage
- Returning to the courseresults example, let’s store the output into a collection called average scores.
- You accomplish this task using $merge
- You won’t see the output from $merge stage in your client because the output documents are stored in the target collection.
Create Instance
- Open MongoDB CLI
- Connect to db training
- Load some sample data
Limit Rows
- Using the $limit operator we can limit the number of documents printed in the output.
This command will print only 2 documents from the marks collection. db.marks.aggregate([{"$limit":2}])
Sort Documents
- Sort documents based on one field=marks
- In ascending order:
db.marks.aggregate([{"$sort":{"marks":1}}]) - In decsending order:
db.marks.aggregate([{"$sort":{"marks":-1}}])
Aggregate Pipeline of Operations
- Aggregation usually involves using more than one operator.
- A pipeline consists of one or more operators declared inside an array.
- The operators are comma separated.
- Mongodb executes the first operator in the pipeline and sends its output to the next operator.
Let us create a two stage pipeline that answers the question “What are the top 2 marks?”
- The operator $group by, along with operators like $sum, $avg, $min, $max, allows us to perform grouping operations.
This aggregation pipeline prints the average marks across all subjects.
# What is the average marks across all subjects
training> db.marks.aggregate([
... {
... "$group":{
... "_id":"$subject",
... "average":{"$avg":"$marks"}
... }
... }
... ])
# OUTPUT
[
{ _id: 'english', average: 62.6 },
{ _id: 'science', average: 77.75 },
{ _id: 'maths', average: 78.5 }
]
# This code is the equivalent of SQL
SELECT subject, average(marks)
FROM marks
GROUP BY subjectMerge
- Now let’s merge the two aggregation above together by
- find the average marks per student (instead of subject as we did above)
- sort the output based on the average from above in descending order
- filter/limit the output to the top 2
Basically: Who are the top 2 students by average marks?
# First part finds the average marks per student by Name
db.marks.aggregate([
{
"$group":{
"_id":"$name",
"average":{"$avg":"$marks"}
}
},
# Here we sort in descending order
{
"$sort":{"average":-1}
},
# Limit/Filter the output to the Top 2
{
"$limit":2
}
])
# OUTPUT
[
{ _id: 'Alison', average: 84 },
{ _id: 'Steve', average: 82.33333333333333 }
]Code
# Load sample data
test> use training
db.marks.insert({"name":"Ramesh","subject":"maths","marks":87})
db.marks.insert({"name":"Ramesh","subject":"english","marks":59})
db.marks.insert({"name":"Ramesh","subject":"science","marks":77})
db.marks.insert({"name":"Rav","subject":"maths","marks":62})
db.marks.insert({"name":"Rav","subject":"english","marks":83})
db.marks.insert({"name":"Rav","subject":"science","marks":71})
db.marks.insert({"name":"Alison","subject":"maths","marks":84})
db.marks.insert({"name":"Alison","subject":"english","marks":82})
db.marks.insert({"name":"Alison","subject":"science","marks":86})
db.marks.insert({"name":"Steve","subject":"maths","marks":81})
db.marks.insert({"name":"Steve","subject":"english","marks":89})
db.marks.insert({"name":"Steve","subject":"science","marks":77})
db.marks.insert({"name":"Jan","subject":"english","marks":0,"reason":"absent"})
# Limit the number of documents to 2
training> db.marks.aggregate([{"$limit":2}])
[
{
_id: ObjectId('6718163c3d4a8d9dbd964033'),
name: 'Ramesh',
subject: 'maths',
marks: 87
},
{
_id: ObjectId('6718163c3d4a8d9dbd964034'),
name: 'Ramesh',
subject: 'english',
marks: 59
}
]
# Sort the documents based on one field=marks in ascending order
training> db.marks.aggregate([{"$sort":{"marks":1}}])
# Sort in descending order
db.marks.aggregate([{"$sort":{"marks":-1}}])
# Aggregate: What are the TOP 2 marks?
training> db.marks.aggregate([
{"$sort":{"marks":-1}},
{"$limit":2}
])
# OUTPUT
[
{
_id: ObjectId('6718163c3d4a8d9dbd96403d'),
name: 'Steve',
subject: 'english',
marks: 89
},
{
_id: ObjectId('6718163c3d4a8d9dbd964033'),
name: 'Ramesh',
subject: 'maths',
marks: 87
}
]
# What is the average marks across all subjects
training> db.marks.aggregate([
... {
... "$group":{
... "_id":"$subject",
... "average":{"$avg":"$marks"}
... }
... }
... ])
# OUTPUT
[
{ _id: 'english', average: 62.6 },
{ _id: 'science', average: 77.75 },
{ _id: 'maths', average: 78.5 }
]
# Find the top two student by name based on their average marks
training> db.marks.aggregate([
... {
... "$group":{
... "_id":"$name",
... "average":{"$avg":"$marks"}
... }
... },
... {
... "$sort":{"average":-1}
... },
... {
... "$limit":2
... }
... ])
# OUTPUT
[
{ _id: 'Alison', average: 84 },
{ _id: 'Steve', average: 82.33333333333333 }
]