Apache Cassandra
Cassandra is a popular open-source distributed NoSQL database system known for its scalability, high performance, and fault tolerance. While it doesn’t have a traditional architectural structure like a building, it does have a robust design that allows it to handle large amounts of data across multiple nodes.
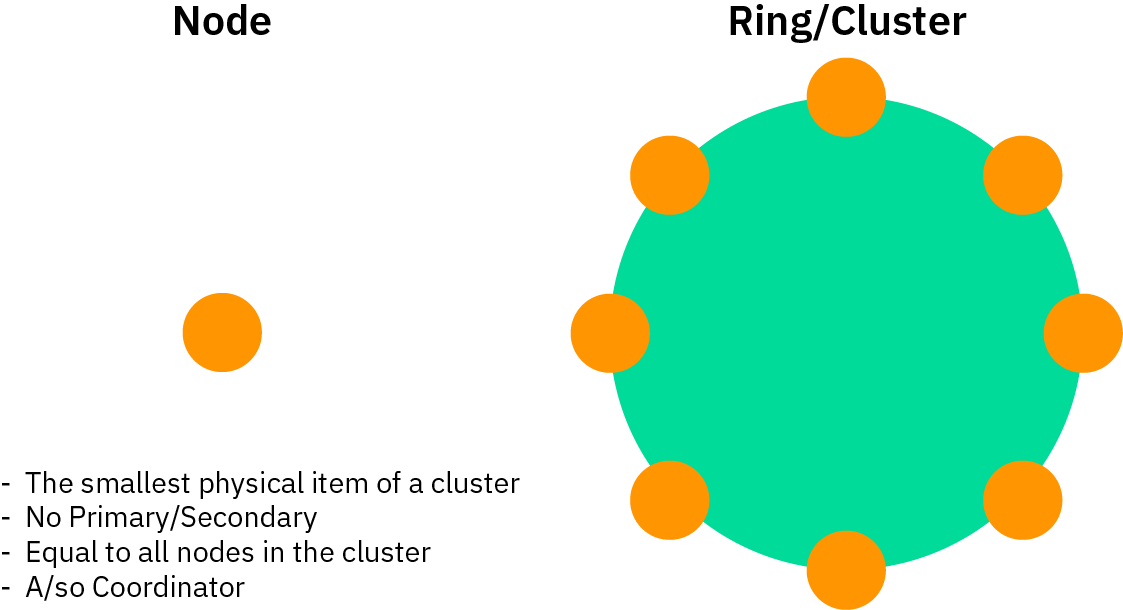
Topology
Cassandra is a distributed system architecture. The basic component of Cassandra’s architecture is
- The standalone unit, node
- It is also known as a single Cassandra.
- Nodes can be added or removed without affecting the system’s availability.
- Each node operates independently and communicates with other nodes through a peer-to-peer protocol.
- Cassandra is designed to be a peer-to-peer architecture, with each node connected to all other nodes. Every Cassandra node can run all database operations and handle client requests independently, eliminating the need for a primary node.
Features
Apache Cassandra is a distributed and decentralized, highly available, fault-tolerant, high write performant, elastically scalable, geographically distributed, and easy to interact with database.
While all NoSQL databases are distributed, you will not find many NoSQL databases that are both distributed and decentralized.
Distributed
Distributed means that Cassandra clusters can be run on multiple machines, while to the users and applications, everything appears as a unified whole. The architecture is built in such a way that the combination of Cassandra application client and server will provide sufficient information to route the user request optimally in the cluster.
- As an end user, you can write data to any of the Cassandra nodes in the cluster, and Cassandra will understand and serve your request.
Decentralized
Decentralized means that every node in the Cassandra cluster is identical. That is, there are no primary or secondary nodes. Cassandra uses peer-to-peer communication protocol and keeps all the nodes in sync through a protocol called gossip.
Gossip Control
How do the nodes in this peer-to-peer architecture know to which node to route a request without a primary node? What if a certain node is down or up?
The gossip protocol enables nodes to exchange details and information, updating each node about the status of all other nodes.
- A node performs gossip communications with up to three other nodes every second.
- The gossip messages follow a specific format and use version numbers to communicate efficiently.
- Each node can build the entire metadata of the cluster (which nodes are up/down, what the tokens allocated to each node are, and so on)

How does data end up in this distributed architecture?
Just remember that Cassandra groups data based on your declared partition key and then distributes the data in the cluster by hashing each partition key called tokens.
- Each Cassandra node has a predefined list of supported token intervals, and data is routed to the appropriate node based on the key value hash and this predefined token allocation in the cluster.
- After data is initially distributed in the cluster, Cassandra proceeds with replicating the data.
- The number of replicas refer to how many nodes contain a certain piece of data at a particular time.
- Data replication is done clockwise in the cluster, taking into consideration the rack and the data center’s placement of the nodes.
- Data replication is done according to the set replication factor, which specifies the number of nodes that will hold the replicas for each partition
Availability
Also, Cassandra is frequently referred to as eventual or tunable consistency in the sense that, by default, Cassandra trades consistency in order to achieve availability.
- But the good news is that developers can control exactly how much consistency they would like to have strong or eventual
- As you may recall according to CAP theorem, NoSQL can be consistent and available at the same time
- Cassandra has been designed to always be available, meaning that if you lose a part of your cluster, there will still be nodes available to answer the service request, though the return data might be inconsistent.
Consistency
Consistency of the data can be controlled at the operation level, and it is tuned between strong consistency and eventual consistency.
- If data inconsistencies exist, these conflicts will be resolved during read operations.
Fault Tolerance
Fault tolerance is an inherent feature of the distributed and decentralized characteristic of Cassandra.
- The fact that all nodes have the same functions, communicate in a peer-to-peer manner, are distributed, and the data is replicated makes Cassandra a very tolerant and adaptable solution when nodes fail.
- The user contacts one node of the cluster. If the node is not responding, then the user will receive an error and contact another node.
- The same architectural flexibility is visible in the way Cassandra scales the capability of the clusters.
Scalability
A cluster is scaled by simply adding nodes, and performance increases linearly with the number of added nodes.
- New nodes that are added immediately start serving traffic, while existing nodes move some of their responsibilities towards the new added nodes
- Both adding and removing nodes is done seamlessly without interrupting cluster operations
- Cassandra gracefully handles large numbers of writes first by parallelizing writes to all nodes holding a replica of your data.
- One important Cassandra fact; by default, there’s no read before write.
- At the node level, writes are performed in memory, meaning no read before and then flushed on disk. On disk, data is appended in a sequential manner with the data being reconciled later through compaction.
Components
Several components in Cassandra nodes are involved in the Write and Read operations:
Memtable
Memtables serve as in-memory structures within Cassandra, buffering write operations before being written onto disk. Typically, each table has an active Memtable. Eventually, these Memtables are flushed to disk, transforming into immutable SSTables (Sorted String Tables).
The triggering of Memtable flushes can occur through various methods:
- Exceeding a predefined threshold for Memtable memory usage.
- Approaching the maximum size of the CommitLog, which prompts Memtable flushes to free up CommitLog segments.
- Setting specific time intervals to trigger flushes on a per-table basis.
These triggers initiate the process where the buffered data in Memtables is persisted onto disk as SSTables, ensuring data durability and efficient retrieval in the Cassandra database system.
Commit log
Commit logs in Cassandra function as append-only logs, capturing all local mutations on a specific Cassandra node. Before you write data to a Memtable, you must record it in a commit log. This process ensures durability in the event of an unexpected shutdown.
Upon restarting, any mutations in the commit log are applied to the Memtables, guaranteeing data consistency and recovery in the Cassandra database system.
SSTables
SSTables (Sorted String Tables) are the immutable data files in Cassandra, storing data persistently on disk. These files are created by flushing memtables or streaming from other nodes.
When you generate SSTables, Cassandra initiates the compaction processes to merge multiple SSTables into one. You should be able to see the new SSTable while the older SSTables become eligible for removal.
An SSTable comprises various distinct components stored in separate files, some of which include:
- Data.db: This file contains the actual data stored by Cassandra.
- Index.db: An index file that maps partition keys to specific positions within the Data.db file, aiding in efficient data retrieval.
- Summary.db: This file provides a sample subset (typically every 128th entry) of the information contained in the Index.db file, offering an overview for quicker data access.
- Filter.db: Cassandra employs a Bloom Filter in this file, which serves as a probabilistic data structure, assisting in determining if a partition key exists in the SSTable without requiring a disk seek.
- CompressionInfo.db: This file holds metadata regarding the offsets and lengths of compressed chunks within the Data.db file, facilitating the decompression of stored data.
These distinct files within an SSTable collectively form an organized structure that enables efficient data storage, indexing, retrieval, and compression within the Cassandra database system.
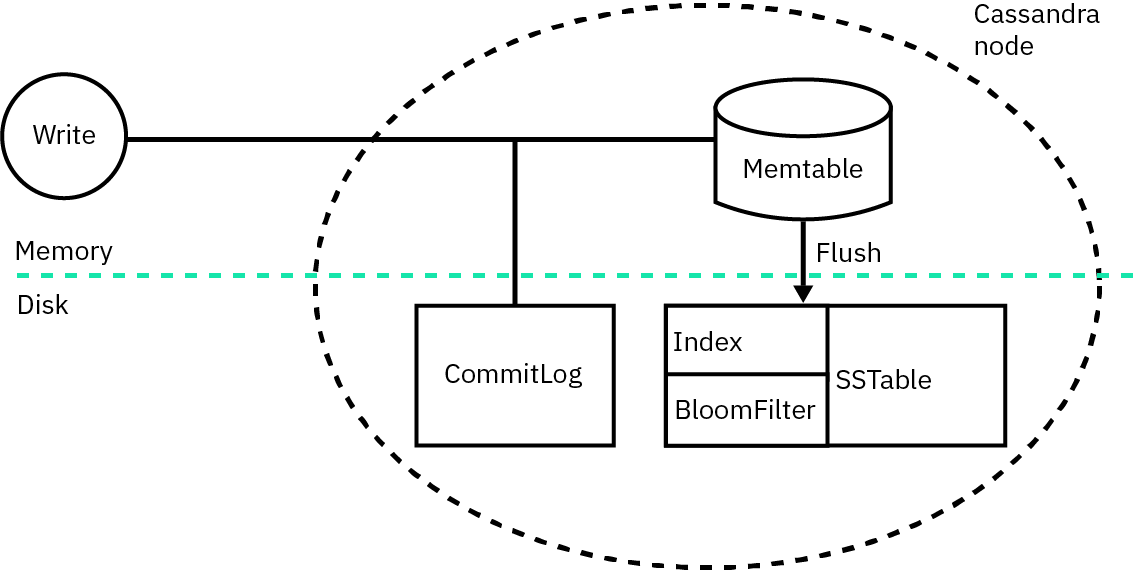
Write process at node level
Writes are distributed across nodes in the cluster, utilizing a coordinator node that manages the operation and replicates data to appropriate replicas based on the configured consistency level.
- Logging data in the commit log
- Writing data to the Memtable
- Flushing data from the Memtable
- Storing data on disk in SSTables
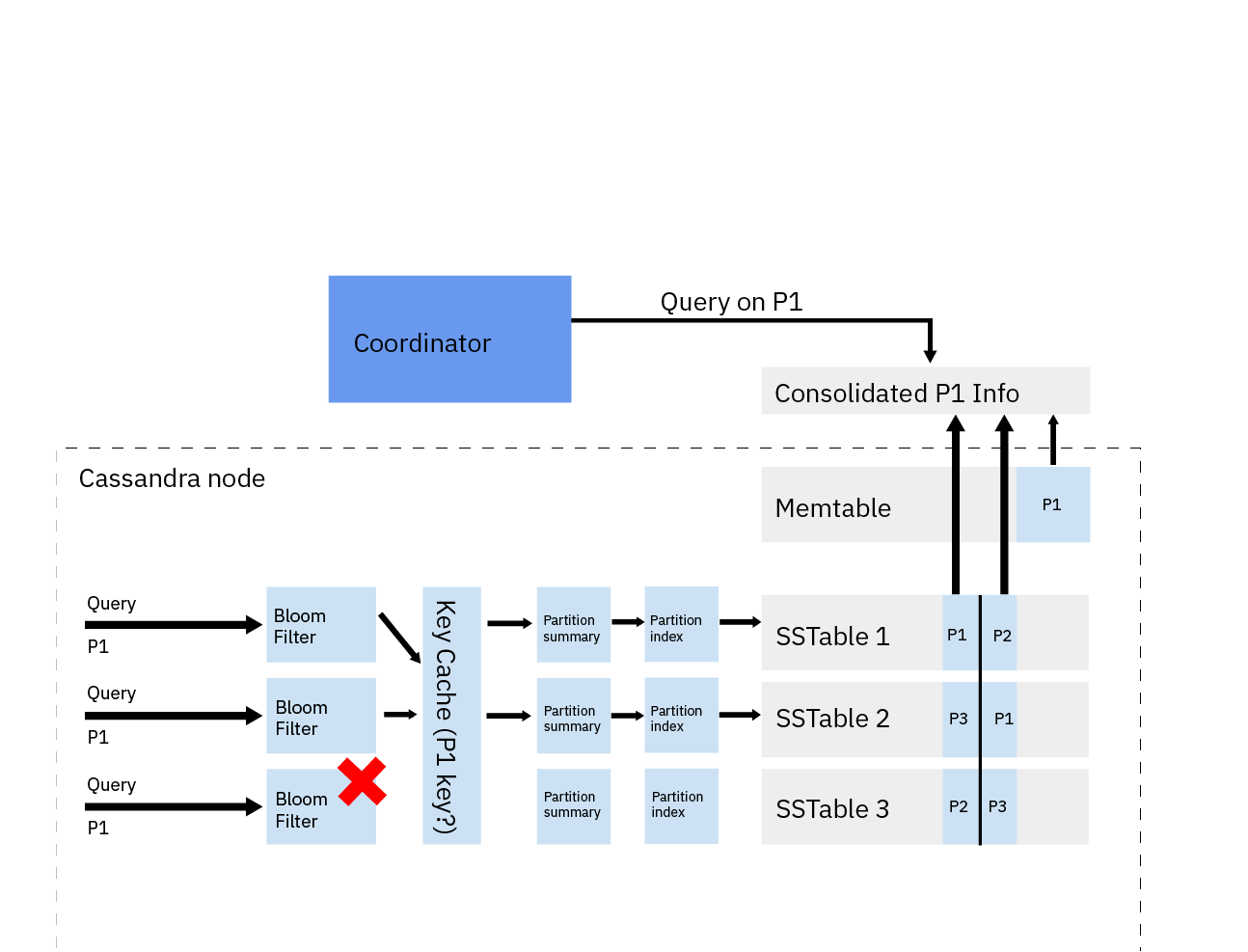
Read at node level
While writes in Cassandra are very simple and fast operations done in memory, the read is a bit more complicated since it needs to consolidate data from memory (Memtable) and disk (SSTables). Since you can fragment data on disk into several SSTables, the reading process needs to identify which SSTables most likely contain info about the querying partitions. The Bloom Filter information makes this selection through the following steps:
- Checks the Memtable
- Checks Bloom filter
- Checks partition key cache, if enabled
- If the partition is not in the cache, the partition summary is checked
- Then, the partition index is accessed
- Locates the data on the disk
- Fetches the data from the SSTable on disk
- Data is consolidated from Memtable and SSTables before being sent to the coordinator
Data distribution
Partitioner: Cassandra uses a partitioner to distribute data across nodes. This consistent hashing algorithm ensures an even data distribution across the cluster, preventing hotspots and facilitating horizontal scaling.
Use Cases
Apache Cassandra is best used by applications that require a db that’s always available
- MongoDB usually covers search-related use cases where the input data can be represented as key document type of entries, but what about the use cases
- Cassandra: where you need to record some data extremely rapidly and make it available immediately for read operations, and all the while, hundreds of thousands of requests are generated?
- Take, for example, recording the transactions from an online shop
- or storing the user access info or profile for a service like Netflix.
- MongoDB caters to read-specific use cases, and thus is very much focused on
- consistency of the data
- Cassandra caters to use cases that require
- fast storage of data
- easy retrieval of data by key
- availability at all times
- fast scalability, and
- geographical distribution of the servers.
- MongoDB has a primary secondary architecture,
- Cassandra has a simpler peer to peer one it has a set of features that sets it apart from other NoSQL solutions:
- distributed and decentralized
- simple peer to peer architecture
- making Cassandra one of the friendliest NoSQL database installations.
- Cassandra
- Always available with tunable consistency
- favors availability over consistency
- fault tolerant
- Extremely fast write throughput,
- while it maintains cluster performance for other operations like read
- Capability to scale clusters extremely fast in a linear fashion without the need to restart or reconfigure the service
- Multiple data centers deployment support, making it extremely useful for services that need to be accessed worldwide,
- Friendly SQL-like query language.
Due to its popularity, Cassandra is sometimes mistaken as being a drop-in replacement for relational databases, but Cassandra by design, does not incorporate three major features of relational databases, and thus should not be seen as a drop-in replacement for a relational database.
- It does not support joins,
- has limited aggregation support,
- and has limited support for transactions.
While writes to Cassandra are atomic, isolated, and durable in nature, the consistency part does not apply to Cassandra as there is no concept of referential integrity or foreign keys.
- If you were thinking of using Cassandra to keep track of account balances at a bank, you probably should look at alternatives.
- If your application has joins and aggregations requirements, then it is best when Cassandra is paired with processing engines like Apache Spark.
Good fit in
Online Services
- When your application is write-intensive
- Number of rights exceeds the number of reads
- For example, storing all the clicks on your website or all the access attempts on your service.
- When your data doesn’t have that many updates or deletes, so it comes in an append-like manner.
- When data access is done via a known primary key called a partition key, the key allows an even spread of the data inside the cluster
- When there’s no need for joins or complex aggregations as part of your queries.
eCommerce Sites
- Storing transactions for analytical purposes, for e-commerce websites, or
- User’s interactions with a website in order to personalize their experience.
- Just storing users profile info for services like session enrichment or granting personalized access to the service.
Time Series
- Where data comes append-wise in a timely manner, like weather updates from sensors where your query could be directed towards what happened to a certain sensor in a specific time interval.
As mentioned previously, Cassandra is a best fit for globally always available types of online services and applications such as Netflix, Spotify, and Uber, but of course, there are many other use cases that can take advantage of its capabilities.
Keyspaces
Cassandra stores data in tables whose schema defines the storage of the data at cluster and node level. So tables are the logical entities that organize data storage at cluster and node level. They contain rows of columns.
- Tables are grouped in keyspaces.
- A keyspace is a logical entity that contains one or more tables.
- A keyspace also defines a number of options that applies to all the tables it contains, most prominent of which is the replication strategy used by the key space.
- It is generally encouraged to use one keyspace per application.
- You can create, drop, and alter your tables without impacting the running updates on your data or the running queries.
- In order to create a table, we need to declare a schema.
- A table schema comprises at least a definition of the table’s primary key and the regular columns of the table.
- Table groups store information regarding several groups, such as groupid, group_name, and for each group, the username and age of their members.
- You can see that the primary key is composed of two columns, groupid and username.
In Cassandra denomination, the groupid column is called the partition key and the username column is called the clustering key.
- First of all, the primary key is basically a subset of the table’s declared columns.
- When creating a table, besides declaring the table’s columns, it is mandatory to specify the primary key as well.
- The primary key, once defined, cannot be changed.
- In Cassandra, the primary key has two roles.
- The first role is to optimize the read performance of your queries.
- Do not forget that the NoSQL systems are query driven data modeling systems, meaning that table definitions can start only after the queries you would like to answer are defined.
- You should build your primary key based on your queries, and the second role is to provide uniqueness to the queries.
- A primary key has two components.
- The mandatory component is called the partition key, and optionally you can have one or more clustering keys. When data is inserted into the cluster in a table, the data is grouped per partition key into partitions, and
- the first step is to apply a hash function to the partition key.
- The partition key hash is used to determine what node and subsequent replicas will get the data. In simpler terms, a partition key determines the data locality in the cluster.

You can see in the diagram and table that data is grouped according to the partition key, groupid, and that each partition is distributed to one of the cluster nodes.
- The partition is the atom of storage in Cassandra, meaning that one partition’s data will always be found on a node and its replicas in the case of a replication factor greater than one.
- So if we want to answer the query all users in group 12, then the query can address only the fourth node and will get the answer.
Define Keyspaces
A keyspace needs to be defined before creating tables, as there is no default keyspace. A keyspace can contain any number of tables and a table belongs to only one keyspace.
- Replication is specified at the keyspace level, and
- you specify the replication factor during the creation of a keyspace but the replication factor can be modified later.

Let’s take a CQL, CREATE KEYSPACE example above:
you can see that besides the name,
we need to set two parameters, class, which refers to the replication strategy, and the replication factor, which is set at each datacenter level.
In this example, we are creating a keyspace called intro_cassandra that
replicates its data, AKA tables partitions five times between the cluster nodes, in 3 nodes from datacenter1 and 2 nodes from datacenter2.
To check if the keyspace has been created, you can use DESCRIBE KEYSPACES or DESCRIBE then the name of the keyspace.
Replication factor
Replication factor refers to the number of replicas of data placed on different nodes while
Replication strategy
Replication strategy determines on which cluster nodes the replicas are going to be located.
After data is initially distributed according to partition key hashed and token pre-allocation, then data is also replicated according to these two pieces of information, replication factor and replication strategy.
Before we move on to some examples of replication factor and strategy, two important notes regarding the replicas.
- In Apache Cassandra, all replicas are equally important. There are no primary or secondary replicas and
- as a general rule, the replication factor should not exceed the number of nodes in the cluster.
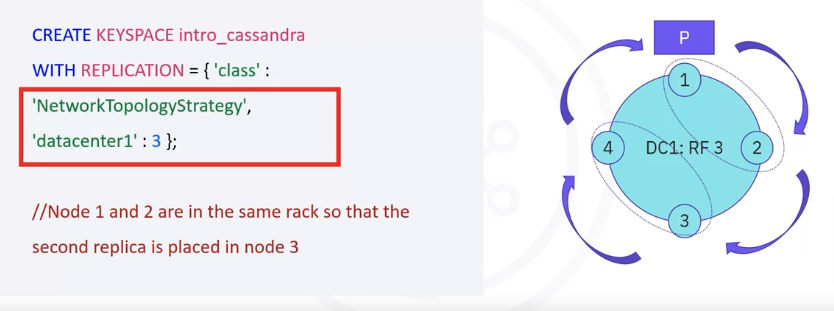
Let’s take a simple example of a
- four-node Cassandra cluster with one datacenter and a keyspace called intro_cassandra defined with replication factor 3.
- In CQL, when we create a keyspace, we need to specify the class as being network topology strategy, the only option recommended for production systems, and specify the replication at datacenter level, in this case, 3.
- Cluster topology indicates that nodes 1 and 2 are in the same rack, while 3 and 4 share another rack as well, we assume that our partition, named P in the diagram has been initially allocated to node 1.
- We have a replication factor of 3, meaning we need to replicate data into two more nodes in order to reach the replication factor of 3.
- Data replication is done clockwise in the cluster while taking into consideration the rack allocation of the servers.
- Since nodes 1 and 2 are in the same rack, Cassandra will try to place the next replica on a node from a different rack, in this case, node 3 and the last replica will be placed on node 4.
- Since two replicas are placed in different racks, the fact that nodes 3 and 4 are in the same rack will not be an issue.
Tables

A table will always be created in an existing keyspace. Cassandra stores data in tables whose schema defines the storage of the data at the cluster and node level.
Data Model
Static & Dynamic
Static
When the table has a primary key that contains only the partition key, single or multiple columns, and no clustering key, the table is called a static table.
Dynamic
When the table has the primary key composed of both partition key or keys, and clustering key or keys, the table is called a dynamic table.
Best Practice
Let’s examine the best practices for achieving high performance, scalability, and efficiency in Cassandra.
Improved read and write performance
An efficient data model enables data to be requested as a single request, reducing complex joins. However, it also enables Cassandra to retrieve data quickly from distributed storage.
Partition correctly
A good partition key restricts hotspots and disproportionately stores the amount of data on a few nodes. It also avoids selecting high-cardinality or frequently updated fields as partition keys and restricts large partitions.
Data duplication
Data duplication supports query patterns and uses primary keys across multiple tables to optimize queries without compromising performance.
Avoid full table scans
Avoiding full table scans minimizes them and range queries without specifying a partition key. Full table scans are resource-intensive, compromising performance for large datasets.
Specify required columns
The data query from Cassandra specifies the SELECT statement’s columns. Obtaining only the required columns reduces the usage of the network bandwidth and minimizes the amount of data transferred between nodes.
Prefer batch updates
The batch update achieves atomicity and consistency for a group of write operations. However, it minimizes the overhead associated with network communication and coordination between nodes in the Cassandra cluster.
Review
We’ve outlined the best practices for Cassandra data modeling:
- Improved read and write performance
- Partition correctly
- Data duplication
- Avoid full table scans
- Specify required columns
- Prefer batch updates
Summary
| Term | Definition |
|---|---|
| BSON | Binary JSON, or BSON, is a binary-encoded serialization format used for its efficient data storage and retrieval. BSON is similar to JSON but designed for compactness and speed. |
| Aggregation | Aggregation is the process of summarizing and computing data values. |
| Availability | In the context of CAP, availability means that the distributed system remains operational and responsive, even in the presence of failures or network partitions. Availablity is a fundamental aspect of distributed systems. |
| CAP | CAP is a theorem that highlights the trade-offs in distributed systems, including NoSQL databases. CAP theorem states that in the event of a network partition (P), a distributed system can choose to prioritize either consistency (C) or availability (A). Achieving both consistency and availability simultaneously during network partitions is challenging. |
| Cluster | A group of interconnected servers or nodes that work together to store and manage data in a NoSQL database, providing high availability and fault tolerance. |
| Clustering key | A clustering key is a primary key component that determines the order of data within a partition. |
| Consistency | In the context of CAP, consistency refers to the guarantee that all nodes in a distributed system have the same data at the same time. |
| CQL | Cassandra Query Language, known as CQL, is a SQL-like language used for querying and managing data in Cassandra. |
| CQL shell | The CQL shell is a command-line interface for interacting with Cassandra databases using the CQL language. |
| Decentralized | Decentralized means there is no single point of control or failure. Data is distributed across multiple nodes or servers in a decentralized manner. |
| Dynamic table | A dynamic table allows flexibility in the columns that the database can hold. |
| Joins | Combining data from two or more database tables based on a related column between them. |
| Keyspace | A keyspace in Cassandra is the highest-level organizational unit for data, similar to a database in traditional relational databases. |
| Partition Key | The partition key is a component of the primary key and determines how data is distributed across nodes in a cluster. |
| Partitions | Partitions in Cassandra are the fundamental unit of data storage. Data is distributed across nodes and organized into partitions based on the partition key. |
| Peer-to-peer | The term peer-to-peer refers to the overall Cassandra architecture. In Cassandra, each node in the cluster has equal status and communicates directly with other nodes without relying on a central coordinator. If a primary node fails, another node automatically becomes the primary node. |
| Primary key | The primary key consists of one or more columns that uniquely identify rows in a table. The primary key includes a partition key and, optionally, clustering columns. |
| Replication | Replication involves creating and maintaining copies of data on multiple nodes to ensure data availability, reduce data loss, fault tolerance (improve system resilience), and provide read scalability. |
| Scalability | Scalability is the ability to add more nodes to the cluster to handle increased data and traffic. |
| Static table | A static table has a fixed set of columns for each row. |
| Table | A table is a collection of related data organized into rows and columns. |
| Transactions | Transactions are sequences of database operations (such as reading and writing data) that are treated as a single, indivisible unit. |
| Term | Definition |
|---|---|
| Cluster | A group of interconnected servers or nodes that work together to store and manage data in a NoSQL database, providing high availability and fault tolerance. |
| Consistency | In the context of CAP, consistency refers to the guarantee that all nodes in a distributed system have the same data at the same time. |
| Dynamic table | A dynamic table allows flexibility in the columns that the database can hold. |
| Keyspace | A keyspace in Cassandra is the highest-level organizational unit for data, similar to a database in traditional relational databases. |
| Lightweight transactions | Lightweight transactions provide stronger consistency guarantees for specific operations, though they are more resource-intensive than regular operations. |
| Partition key | The partition key is a component of the primary key and determines how data is distributed across nodes in a cluster. |
| Primary key | The primary key consists of one or more columns that uniquely identify rows in a table. The primary key includes a partition key and, optionally, clustering columns. |
| Replication factor | The replication factor specifies the number of copies of data that should be stored for fault tolerance. |
| Replicas | Replicas in Cassandra refer to the copies of data distributed across nodes. |
| Replication strategy | The replication strategy determines how data is copied across nodes. |
| Secondary indexes | Secondary indexes allow you to query data based on non-primary key columns. |
| Static table | A static table has a fixed set of columns for each row. |
| Table | A table is a collection of related data organized into rows and columns. |